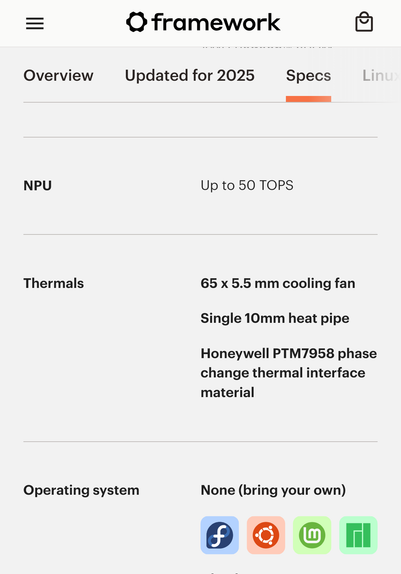
One year ago the #Framework13 AMD Ryzen 300 AI series got released. It has a neural processing unit (NPU).
Unless you compile your own kernel and a bunch of modules and toolchains the NPU hardware is still unusable on any Linux distribution out there.
One year later and there are zero end users on that NPU on Linux. It's dead hardware.
When (if at all) it's integrated smoothly, the NPU hardware will be outdated hardware.
#AMD 🤝 #Framework that's what Linux-first looks like? 💩🏆