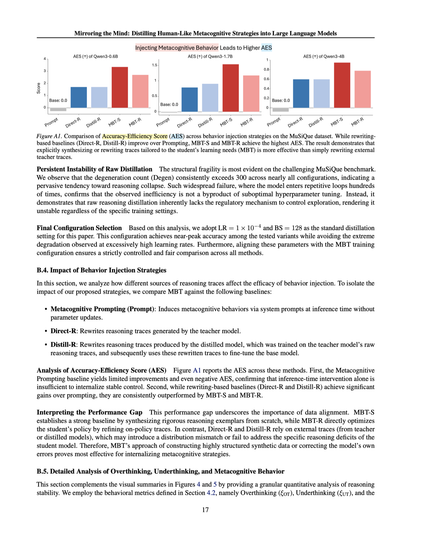
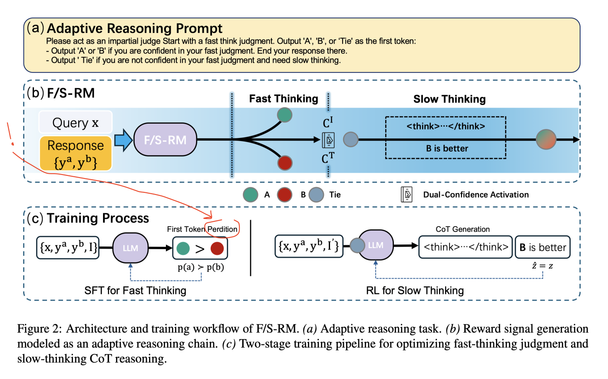
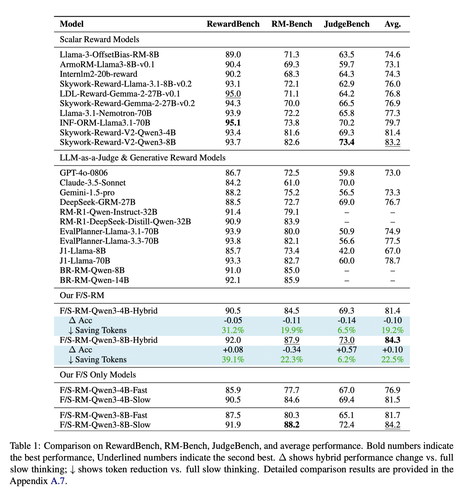
As recommended in #StrategicReflectivism (https://doi.org/10.48550/arXiv.2505.22987), #AI models can increase efficiency by tactically reflecting on initial answers.
There are a few ways to do this with #LLMs.
Kim et al. recently tested "metacognitive behavioral tuning": https://doi.org/10.48550/arXiv.2602.22508