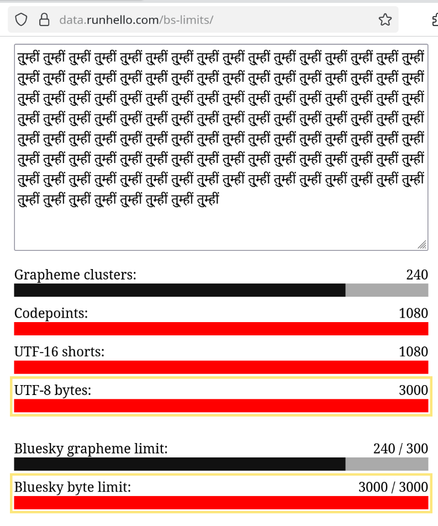
Got nerdsniped by a request from @thisismissem.social and made a little visualizer tool demonstrating the various ways you can represent "how long is this string?" in Unicode:
https://data.runhello.com/bs-limits/
- Bytes (in the standard UTF-8 recording)
- UTF-16 (irrelevant except in JS, where it's relevant)
- Codepoints (unicode characters)
- Grapheme clusters (the visual "characters" you see on screen)
And how the divergence of the two relates to Bluesky's "unusual" post limit rules.