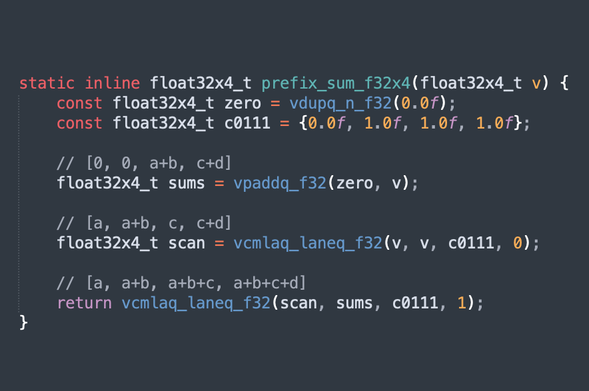
Three instruction NEON float prefix sum. I'd wanted to abuse FCMLA (floating-point complex multiply accumulate) for non-complex arithmetic for so long, and I finally came up with something :)
With two unnecessary multiplies to save one instruction, this may only work out on Apple CPUs, but it's a bit of fun.
(For loops you can broadcast the carried value with vfmaq_laneq_f32(scan, ones, prev, 3) for three multiplies saving two instructions. LLVM fights you on that, though.)
[oops, see reply]