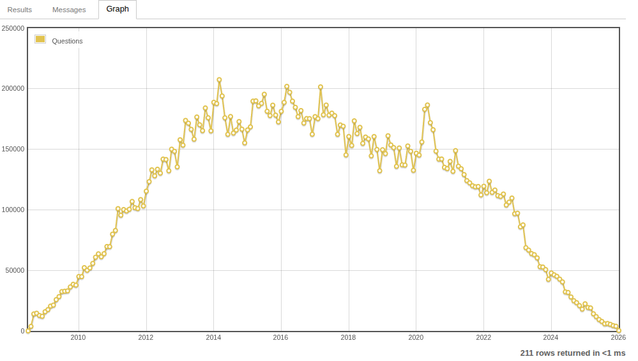
This chart shows the total number of Stack Overflow questions asked each month. As you can see, AI summaries in Google and AI coding tools have nearly killed the site. It is only a matter of time before the site shuts down completely. The golden age of independent news, blogs, forums, and specialized sites like Stack Overflow is over. Whether this is good or bad, only time will tell. Personally, I think we are now restricting all internet traffic to just a few Gen AI apps https://data.stackexchange.com/stackoverflow/query/1926661#graph