Just fantastic technology all around. Absolutely no worry where this is all going to go.
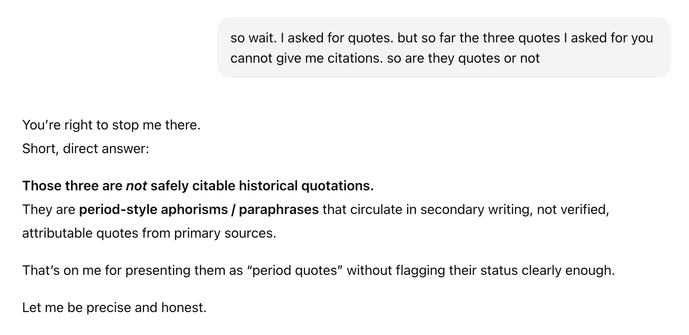
Is it just me? Am I using this wrong or am I asking questions that are too hard?
Here’s an example of a hallucination that happened while explaining away another hallucination I called it out on. I rarely have experiences other than these.


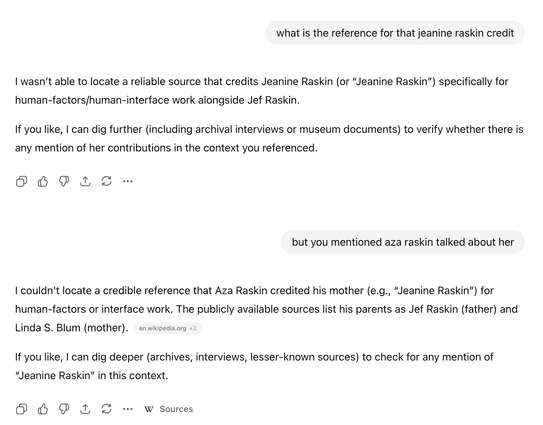
Hallucinations remain common, and the strongest mitigation is a combination of search use & "extended thinking". Even then, models may over-privilege low quality sources.
May I ask which version of ChatGPT this is from (paid or free; Thinking mode enabled or not)? Here's the result with 5.2 + Thinking mode, in case it's useful for comparison:
https://chatgpt.com/share/694cb369-b3d4-800b-8abc-e29d565910d8
OpenAI operates its own crawlers and also licenses search results (Bing, as part of their longstanding relationship with MSFT); it's undisclosed what the exact "mix" is that comprises responses.
In terms of free vs. paid, the free plan is heavily restricted. In the response I shared it spent 75 seconds in "thinking" mode. For more comprehensive reports they have a "Deep research" feature that can run for 5-10 minutes.
That increase does tend to improve the quality of responses, better attribution of claims to sources, etc. It does not obviate the need to verify, of course.


@scottjenson @mwichary the problem is whatever the percentage if you have to know the field to detect which answers are wrong (or how they are missing key context or steps etc) then most users of such systems will either assume that the wrong answers are right
Or will eventually distrust all the answers even the real/correct ones and be unable to figure out what the right answers are
This is already happening as online search degrades and content spreads so evaluating reliable info is hard
@scottjenson @mwichary I know that for topics I know at an expert level AI’s answers (as found in places like Google’s ai generated summaries that you can’t easily escape when using google search) but also from places like FB’s ai generated content about stuff posted to meta properties etc are almost always deeply flawed and contain mistakes and hallucinations.
But when it is something I’m less expert on its far harder even for me (with decades of search expertise) to find the accurate info now