

Hey #Rust,
how dare you look so elegant as a systems programming language! 💅
Hey #Rust,
how dare you look so elegant as a systems programming language! 💅
@calisti Oopsie!😳
Fixed it - thank you! 🙂
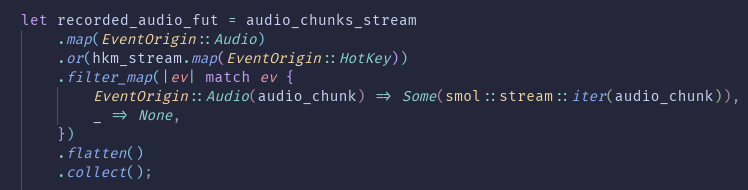
@janriemer Confused about the first screenshot: you merge in a hotkey stream, to just filter-map it out again in the following combinator?
Does the hkm stream just need to be polled, discarding its yielded items?
@calisti Yes, it yields a unit type every 100ms as long as you press the hotkeys.
What this means is: you record audio (this is the audio stream) as long as you press the hot keys.
In the end we are only interested in the audio data.
The hot key stream basically acts as a start/stop mechanism for the audio stream. 🙂
@janriemer Ah, interesting! So are you setting some Boolean state depending on the hot key stream outside the screenshot?
And when it flips, you just stop polling the collected future?
There’s one thing I’m wondering if it has a detrimental effect:
`StreamExt::or` says it prefers the main/local stream if both are ready. Might this mean you could in some situations end up keeping on processing audio, effectively missing to poll the hot key stream (since both streams are ready)? (1/2)
Shouldn’t the hot key stream be the main/local stream, since it less often yields new items, thus less often pausing the `or`-merged (audio) stream?
And I’m also curious: is this a microcontroller project? (2/2)
@calisti Yes, you might be right here! I think I need to understand the `or` stream better.
I'm a bit confused now.😄
@janriemer I’m also slightly confused. 😅
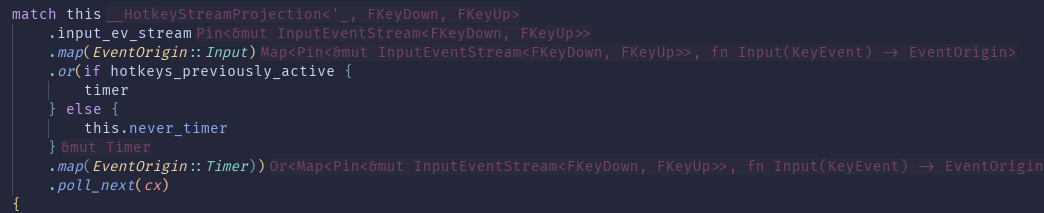
Are the left and right screenshot part of the same input and audio handling system, or are they unrelated?
@calisti They are related.
The right screenshot is part of the hotkey stream (refered to as `hkm_stream` in the left screenshot).
So the left screenshot is "higher level" than the right screenshot.
Sorry for the confusion.
I'm using whisper_rs, which is a wrapper around the awesome whisper.cpp lib:
https://github.com/ggml-org/whisper.cpp/
https://lib.rs/crates/whisper-rs
There are quantized models in all kinds of sizes over on huggingface:
https://huggingface.co/ggerganov/whisper.cpp/tree/main
The cool thing is: they can completely run on the CPU - no graphics card required!
I'm using the small model and I'm amazed by it's quality!
As a test, I've read a few sentences of a german article to the model and let it transcribe it...
1/2
...and it even got quotes correctly transcribed, e.g.
"Es gibt viel zu tun", sagte Person X.
Even something like "denglisch" it can do:
"Wir werden heute unseren Code _releasen_".
Ofc, sometimes there are some errors, but all in all I'm pretty impressed and I think it will be quite useful (not having to type on the keyboard all the time).
I think this (A11y) is one area where "AI" is actually quite useful (another one, IMO, is local semantic search on known data).
2/2
@janriemer Oh, neat. I had incorrectly assumed, whisper was OpenAI’s speech recognition API.
Please keep me updated. There’s plenty of use cases for an application like this, especially if it’s processing locally and its code is open source. (Even if the model itself is only “open weights” but not “open source” in terms of full transparency as it comes to training data and process.)
> Oh, neat. I had incorrectly assumed, whisper was OpenAI’s speech recognition API
Hm...not quite sure if we have a misunderstanding here:
Whisper is originally from OpenAI and made open source:
https://github.com/openai/whisper
whisper.cpp is an optimized version of it that doesn't require so much compute. It is made possible by the awesome llama.cpp community project:
https://github.com/ggml-org/llama.cpp
@calisti Yes, I'll keep you updated! 🙂
(and ofc the project will eventually be open source 😉)
@calisti Oh, and to answer your actual question...😄
> Have you considered using ollama or similar local LLM runners?
Yes and no. 🙃
I'd be interested in the following:
Run an LLM over the transcribed audio text and insert paragraphs at "the right points".
But LLMs require so much compute power and I don't want to require a graphics card for this project.
So MVP => transcribe audio. I'm already thinking about how to conveniently insert paragraphs _manually_ into the result, but no idea yet.
@calisti Yes! Very interesting side quest indeed! 🤓
Also, another side quest: actually _streaming_ the audio into the model.
Currently, all audio is collected first and then fed into the model as a whole.
@calisti No, unfortunately, it is not multi-modal.
So you'd have to wait for the transcribed text and then pass that into another LLM (which obviously increases latency by a lot and I don't want to go that route (yet?)).
@calisti Ah, I see where you're going with this now. Yeah, that would be neat.
I'm still thinking about automatically inserting paragraphs - something like this:
https://github.com/segment-any-text/wtpsplit
But this is something for the far future. 😉
@calisti There is a lot of context missing in the screenshot - sorry for the confusion.😔
No, there is no boolean flag. The hotkey stream ends, when you _release_ the hotkeys.
> effectively missing to poll the hot key stream
Oh, I think you're totally right!😬
Thank you for pointing this out and taking the time to think about this!
So far in my (manual) tests it "immediately" stops the stream, when I release the hotkeys (so it "works"?).
Guess I need to do some tracing - my head hurts now.🥴
Ok, @calisti, I _think_, I've figured it out now (please read until the later parts of the toots as they are the most important)!🤓
Tldr; The `or` or `race` operators _on their own_ are not suitable for cancelling streams! One needs a `StopToken` or enum value _within the stream_ that signals cancellation/allows for short-circuiting.
1/?
My whole assumption on how `or` (or `race`) work, was wrong!
I thought, as soon as one stream yields `Ready(None)` the whole merged stream would stop. But this is wrong!
Example (slightly made up syntax):
[Ready(Some(1), Ready(None))]
.or([
Ready(Some(2)),
Ready(Some(3)),
Ready(None),
])
...will result in [1, 2, 3]. I thought it would result in [1]. 🤦
This whole problem is obviously related to _async cancellation_, so I've dug a little deeper:
2/?
One solution for cancelling the audio stream is to _have an enum value emitted by the hotkey stream that indicates release of the hotkey press_.
Also, now we need to apply _your proposed solution_ of having the hotkey stream as the main stream.
We can then do something like this (again simplified syntax):
hk_stream
.or(audio_stream)
.take_until(|ev|
matches!(ev, EvOrigin::HotKey(HkEv::Released)
)
.filter_map(...) // logic as before
.collect()
3/4
Other solutions use some kind of stop token, with which you can cancel "at a distance" with the help of channels...:
https://github.com/jonhoo/stream-cancel
https://docs.rs/stop-token/latest/stop_token/index.html
https://docs.rs/futures-time/latest/futures_time/stream/trait.StreamExt.html#method.timeout
...but I think I'll go with the enum value and `take_until` solution.
Thank you so much for spotting my mistake! ❤️ My understanding on `or` or `race` combinators were totally wrong and this has helped me a lot to understand them better.
4/4
@janriemer > So far in my (manual) tests it "immediately" stops the stream, when I release the hotkeys (so it "works"?).
This isn’t intuitive to me. The audio chunks stream should keep on yielding chunks regardless of the hotkey stream.
However, you are flattening the chunks’ items, then collecting the whole bunch. It seems to me as if you are aggregating chunks’ flattened items until the audio chunks stream stops yielding. Is there another external factor that makes it stop? (1/2)
@calisti Oh no, I think we have a "race condition" in our answers 😅
See here (which I've posted before your recent answers):
https://floss.social/@janriemer/115162514693464844
Let me finish that thread real quick and then I'll come back to this, ok? 🙂
Ok, @[email protected], I _think_, I've figured it out now (please read until the later parts of the toots as they are the most important)!🤓 Tldr; The `or` or `race` operators _on their own_ are not suitable for cancelling streams! One needs a `StopToken` or enum value _within the stream_ that signals cancellation/allows for short-circuiting. 1/? #Rust #RustLang #AsyncRust #Async
@calisti Now I come back to your question here🙂
If I understand this correctly (not 100% sure!), it is as follows:
The audio stream is polled so often (by awaiting the `collect` in the left screenshot) that it will most often return `Pending`, because audio coming in is slower than collecting the stream itself.
So we will (in 99,999999% of cases?) get Pending values from our audio stream, which lets our hotkey stream to run.
1/2
But as you've said, this is actually a bug, because we _rely on the audio stream to return `Pending`_ fairly often.
If this was (for whatever reason) not the case, and it would only ever yield Ready, our hotkey stream would never run (as you've correctly pointed out previously!).
Urgh! What a gnarly hidden bug! This has manifested itself, because my assumption about `or` (and `race`) was totally wrong (see here: https://floss.social/@janriemer/115162570540638966)!
Thank you for enlightening me!🤗
2/2
@[email protected] My whole assumption on how `or` (or `race`) work, was wrong! I thought, as soon as one stream yields `Ready(None)` the whole merged stream would stop. But this is wrong! Example (slightly made up syntax): [Ready(Some(1), Ready(None))] .or([ Ready(Some(2)), Ready(Some(3)), Ready(None), ]) ...will result in [1, 2, 3]. I thought it would result in [1]. 🤦 This whole problem is obviously related to _async cancellation_, so I've dug a little deeper: 2/?
@janriemer This doesn’t explain yet, why in your original version the audio chunks stream ever stopped yielding chunks.
You releases the hotkey and the collect future eventually stopped collecting, returned ready and provided you with the collected flattened stream of audio data.
How did the audio chunks stream stop yielding new chunks? Does this indicate there must be another bug?
@calisti Oh, right, I've forgotten to mention it:
After the merged stream has been collected with the audio data, we stop the audio stream (I use cpal crate for recording audio from microphone):
https://docs.rs/cpal/latest/cpal/traits/trait.StreamTrait.html#tymethod.pause
@calisti Hm...but I want to record audio as long as the future is not complete (aka as long as the hotkeys haven't been released).
So shouldn't the pause be _after_ the collect future resolves?
@calisti I think what you try to get at is:
There will be some audio data "lost" (no cancel safety) after hotkeys have been released, but these are microseconds (or even less) and our "contract" is:
every audio chunk that might have been recorded after hotkeys have been released and .pause() called on the audio stream, can be discarded/ignored, because we are not interested in it.
@janriemer What I mean is: in your original left-side screenshot, the audio chunks stream wouldn’t stop yielding new chunks by itself.
Therefore, the flat mapped audio data would not stop yielding data into the collector by itself.
For some reason, though, you observed the audio stream stopping. How did that work? (1/3)
The flat map returning None in the hot key case does not stop the stream. It merely filters out the hot key event from the resulting stream that’s passes on to the collector.
The collector should never become ready until the stream fed into it ends (with poll_next yielding Ready(None)). This can only happen if the audio chunks stream at the top stops yielding new chunks of data into the flat map combinator. (2/3)
Please see:
https://floss.social/@janriemer/115163244125815519
It is because how `or` works (or am I actually misunderstanding!? I hope not 🥺):
When `or` receives a `Pending` on one side and a `Ready(None)` on the other side (in this case the sides don't matter), _the stream ends_.
Edit: I think what I'm saying is wrong! 😢
@[email protected] > Therefore, the flat mapped audio data would not stop yielding data into the collector by itself. Yes, it will stop yielding into the collector, when we have the following state (made up syntax): [...,..., Ready(None)].or([Ready(audio), Pending, Ready(audio)]) Note the `Pending` in the audio stream. For the original code in the sreenshot to work, we rely on the audio stream to _at least once_ yield Pending after Hotkey stream has finished => then the collect future resolves.
@calisti Hm...thinking about this some more, what _I'm_ saying doesn't make any sense!
Only because one stream has yielded Ready(None) and the other Pending shouldn't stop the merged stream!
Honestly, now, I don't know why my code works. 😄
Wow, this is scary! 😬
@janriemer Does the hot key stream end (yield Ready(None)) once the hot key is released?
In that case, your assessment is entirely correct:
The Stream impl of the Or combinator struct does allow the hot key stream to end the entire stream:
https://docs.rs/futures-lite/latest/src/futures_lite/stream.rs.html#2621 (1/2)
@calisti Oh, wow, thanks! I thought the stream would end _no matter on which side of the `or`_!
So to confirm I've just tried the following:
swap audio stream and hotkey stream (hotkey stream is now the main stream, audio stream is in the `Or` struct).
And now the application _hangs_, which is expected, because the audio stream never finishes!
Wow, such a "lightbulb-moment" for me!
Thank you for diving this deep into it with me and being so persistent! 🤗 I've learned so much! 🤓
@calisti Also, you're totally right regarding the bug of not pausing the audio stream correctly:
I've just tested speaking into my mic _without pressing the hotkeys_ and what I was saying then was also transcribed as soon as I pressed the hotkeys and released them. Oopsie! 😄
So clearly starting and stopping the audio stream is currently not working correctly.
@calisti Found the bug regarding start/stop of audio stream (and fixed it  ):
):
Apparently, for some hardware it is enough to _initialize_ the audio stream with cpal for starting the recording without calling .start():
Method for initializing:
https://docs.rs/cpal/latest/cpal/traits/trait.DeviceTrait.html#method.build_input_stream
Method for starting the stream (for some hardware, stream has already started before calling this method - see docs on this method):
https://docs.rs/cpal/latest/cpal/traits/trait.StreamTrait.html#tymethod.play
Same for stopping the stream:
https://docs.rs/cpal/latest/cpal/traits/trait.StreamTrait.html#tymethod.pause
1/2
@janriemer What you wrote here is right!
I wasn’t aware that your hot key stream ends once the key is released.
> Therefore, the flat mapped audio data would not stop yielding data into the collector by itself.
Yes, it will stop yielding into the collector, when we have the following state (made up syntax):
[...,..., Ready(None)].or([Ready(audio), Pending, Ready(audio)])
Note the `Pending` in the audio stream.
For the original code in the sreenshot to work, we rely on the audio stream to _at least once_ yield Pending after Hotkey stream has finished => then the collect future resolves.
@calisti To minimize misunderstandings or accidental left out info on my part (and you having to guess), I'll upload the code (privately) to my GitLab.
Do you have GitLab (I think you can also login with a GitHub account there)?
I'll invite you then into the project, so you can try for yourself and see the whole code (if you want).
Currently, used microphone is hard coded though (needs to have "Sennheiser" in it's name, lol).



