Na das kann ja zukünftig noch heiter werden.
Na das kann ja zukünftig noch heiter werden.
Ja, man hört jetzt häufiger von sowas.
Ich würde ja sagen: (Hoch)schulen müssen damit leben lernen, dass Studierende LLMs als Werkzeug benutzen und dementsprechend die Aufgaben daran anpassen.
Wie haben die Fernschulen denn früher überprüft, dass die Studierenden ihre Texte selbst geschrieben und nicht von einem Computer oder Freunden haben übersetzen lassen?
Ich hab z.B. neulich einen Artikel gelesen, dass Studierende in den US inzwischen ihre Bildschirme abfilmen und ihr ganzes Recherche-Material aufheben sowie Zwischenversionen ihrer Arbeit etc. (was man natürlich auch alles faken könnte).
Und… ja das wäre eine mögliche Lösung, aber dann sollte es auch als Teil der Aufgabe definiert werden und im Umfang und Komplexität der Aufgabe berücksichtigt werden.
Eine lückenarme Dokumentation ist schließlich auch Arbeit.
@deusfigendi @nerdherz an Unis kann man das in einigen Fächern recht einfach machen. Das Studenty muss seine Arbeit selbst vorstellen. Wer keine Fragen beantworten kann, fällt durch. Spätestens bei der Bachelor Arbeit bespricht man den Inhalt der Kapitel eh direkt miteinander.
LLMs helfen im Grunde nur bei Dingen, die andere schon vorher gemacht haben und damit nur bei Abschreiben.
@nerdherz
Sowas passiert, wenn Institutionen Technologie einsetzen, ohne sie auch nur im Ansatz zu verstehen. In Software gegossene Hilflosigkeit.
Ich kenne auch deutsche Hochschulen, die sowas nutzen.
@koehntopp Ich schrieb ja in https://www.arminhanisch.de/2025/05/sind-hausarbeiten-tot/, dass das Schulsystem sowas nicht gebacken bekommt. Solche Geschichten tun weh.

Sind Hausarbeiten in LLM-Zeiten tot? Machen wir die Ausgangsbasis provokant: es gibt “KI”, die geht nicht mehr weg und deswegen sind Hausaufgaben oder schriftliche Hausarbeiten tot. In der Schule gibt es sie noch, also hängt Schule auch hier der Entwicklung hinterher bzw. muss sich etwas anderes als Hausarbeiten einfallen lassen. Ende Blogpost.
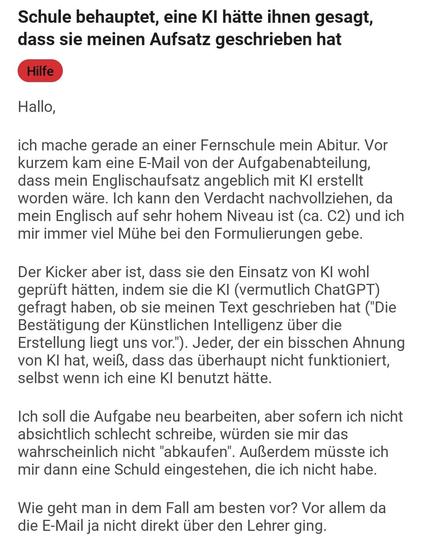
@meta_blum https://www.reddit.com/r/abitur/s/gfeWi4LzSm
Habs auch gerade reineditiert
Es wäre natürlich möglich, ein LLM selbst zu hosten, auf einem Computer, der nicht mit dem Internet verbunden ist und vielleicht mit Strom von den Solarzellen auf dem eigenen Dach (mietwohnung: balkonsolaranlage).
Der Gedanke private Daten in ein mit dem Internet verbundenen Chat-Programm hochzuladen - geschweigedenn die privaten daten einer dritten person - läßt mich eibfach nur erschauern.
Und die, die es trotzdem tun: Die DSGVO sieht dafür eine Geldstrafe von 20 Millionen Euro - oder 4% des Jahresumsatzes wenn diese Summe höher als 20 millionen ist - vor.
Ein LLM von Null selbst zu trainieren, ist nicht machbar. Aber Llama oder eine Reihe anderer fertiger LLMs herunterzuladen und zu verwenden ist möglich. Klar, ein paar Gigabyte RAM sind nötig und mit einer leistungsstarken GPU (wie es sie in Gamer-PCs gibt) oder NPU (wie es sie in hochpreisigen Smartphones gibt) läuft es schneller als ohne. Die beantwortung eines Prompts kann sekunden oder minuten dauern - muss aber auch nicht mit tausenden anderen usern geteilt werden.
@Natanox @Life_is @daswarkeinhuhn @nerdherz
nö...
Wir hatzen letztens nen Studenten, der ein LLM benutzt hat, um Zusammenfassungen von Python-Routinen zu erzeugen, die alle eine bestimmte nicht-öffentliche Bibliothek benutzen (für die musste er das Modell erstmal nach-trainieren). Der hat ein paar ziemlich fähige Modelle verglichen, die alle auf ner Workstation für ein paartausend Euro liefen.
Die meisten davon hätten auch auf nem Laptop laufen können, nur dann halt etwas zu langsam für die geplante Anwendung.
=> Kurze Texte zusammenfassen und so geht inzwischen ganz gut lokal. Längere Texte *verfassen*, auf der anderen Seite... jau, das wird schwieriger. Output von ChatGPT zu erkennen dürfte einfacher sein als ihn zu erzeugen.
@Life_is @daswarkeinhuhn @nerdherz
Strafen gehen immer an den Staat.
Schadensersatz ist davon unabhängig.
Zwar ist es einfacher von jmd Schadensersatz zu fordern, der wegen dieser Tat verurteilt wurde - aber diesen Schaden muss man auch erst belegen.
Das ist richtig. Es sollte die Verwender von LLMs nur noch mehr motivieren, sich an Gesetze zu halten, da sie sowohl vom Staat als auch zivilrechtlich von den betroffenen zur verantwortung gezogen werden können.
OJ Simpson wurde vom Staat des Doppelmordes freigesprochen, von einem Zivilgericht schuldig gesprochen und ging am ende in den knast, weil er seine vom gerichtsvollzieher beschlagnahmten pokale per raub zurückholte.
Ich finde den post im thread, auf den ich antworten möchte, nicht wieder. Aber meine antwort ist: in der bildung (schule, uni, sonstwas) sollte GPT-software überhaupt nicht als tool/arbeitsmittel verwendet werden, sondern nur als Thema des Unterrichts vorkommen. So wie im Geschichtsunterricht der zweite Weltkrieg thematisiert werden sollte, aber nicht ein krieg ausgeführt werden sollte.
Anderes beispiel: in der grundschule wird das kleine und große einmaleins nicht in der form gelehrt, möglichst schnell am taschenrechner zu tippen oder die kugeln am abakus zu verschieben. Es geht ums kopfrechnen.
Vortrag von @RainerMuehlhoff anschauen
Prognose für die Zukunft ist, daß alle Prozesse, in denen KI schreiben und bewerten könnte, deswegen kollabieren werden.
Bereits passiert bei Bewerbungen, Aufsätzen an US Universitäten und in Zukunft Verwaltungen.
Da war ich am Montag in einer Video Konferenz auf Einladung von Holger
https://www.eurosoc-digital.org/en/project/youthgovai-2
Es gibt eine Verbindung zu https://it.yougov.com/ und die haben ein Dokument wie Schüler:innen sich die Bewertung von #AI selbst angeschaut haben. Leider auf Italienisch. Das einzige sinnvolle wäre ein Projekt anzustossen, wo solche Inhalte im Unterricht erarbeitet werden @RainerMuehlhoff ?
Kaputte KI in einem kaputten auf Noten ausgerichteten Schulsystem geht schief
Studie in der History gefunden
Viel Spass
Bei uns an der Uni wird sowas routinemäßig nicht gemacht, aber in Verdachtsfällen scheinen einige Kollegen das so zu machen.
Es gibt da aber große Streuungen zwischen verschiedenen Tools, die die Wahrscheinlichkeit einschätzen, dass ein Text per LLM erzeugt wurde -- manche sind da extrem "trigger happy".
Gerade bei "einfachen" Aufgabestellungen, die sich mit Standardformulierungen behandeln lassen, würd mich garnicht wundern, wenn viele Antworten wie aus dem LLM aussehen.
Ich würd die Leute mal fragen, wieviele Tools übereinstimmend behaupten, der Text sei künstlich, und mit welcher Wahrscheinlichkeit.
Außerdem natürlich wichtig: Fehler einbauen würde zwar "helfen", aber kreativere Texte zu schreiben ebenso (und ist in der Regel auch git für die Note)



