« Langue de Molière », « langue de Racine » (https://mastodon.online/@f_moncomble/114575877138524904)… et pourquoi pas « langue de Jul » ?
Ça vous parait insensé ? Figurez-vous qu’on a fait une petite expérience, 20 minutes montre en main…

« Langue de Molière », « langue de Racine » (https://mastodon.online/@f_moncomble/114575877138524904)… et pourquoi pas « langue de Jul » ?
Ça vous parait insensé ? Figurez-vous qu’on a fait une petite expérience, 20 minutes montre en main…
@jbouton @tract_linguistes Ça peut se faire ! En attendant, un autre exemple dans ce pouet :
https://social.sciences.re/@tract_linguistes/114592593439426708
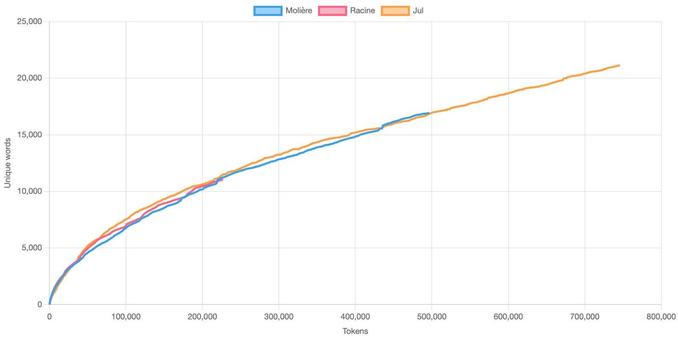
Attaché : 1 image · Avertissement de contenu : Entre Balzac, Dumas et Flaubert, lequel selon vous utilise le vocabulaire le plus riche dans son oeuvre (le plus grand nombre de mots différents rapporté au nombre total de mots utilisés). Lequel en utilise le moins, et donc se répète le plus, en termes de vocabulaire ? #devinette #battle Faites votre pari avant de regarder la réponse
@f_moncomble @jbouton @tract_linguistes il faudrait un gros corpus quand même en nombre de mots, écrit par une seule personne, dans un domaine assez homogène, en libre accès et déjà numérisé.
Genre une thèse de doctorat et tous les articles de la même personne sur HAL? Mais pas une thèse en sciences humaines, elle serait bourrée de citations d'autrices et auteurs divers... Une thèse en chimie, en géographie, jsp...
Plus le domaine est pointu et le texte utilitaire ou scientifique, plus la courbe devrait plafonner après la première phase de montée rapide