@healthchecks_io folks, is there any chance you had a TCP misconfiguration around 08:00 UTC today? Some of our HTTP pings couldn't establish the connection and it triggered an alert.
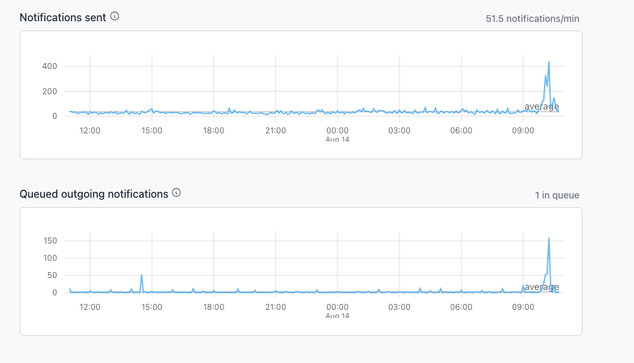
@comsey no code deploys or configuration changes around that time. There *were* several outgoing webhook timeouts around that time which caused the spike in the queued notifications graph. But there were also successful outgoing webhooks during the same time period.