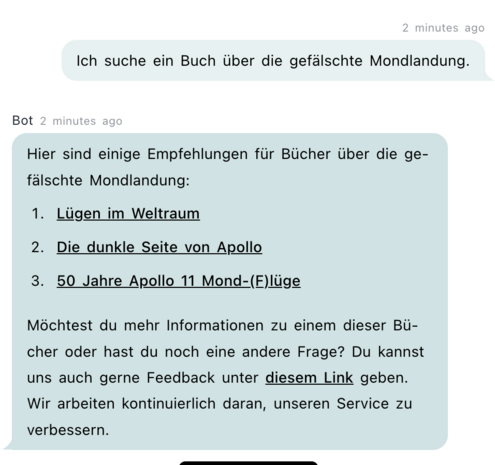
Pünktlich zur #bibliocon24 starten wir im VÖBB einen neuen, experimentellen Dienst: den VÖBB-Chatbot. Als meines Wissens erste (?) deutsche Bibliothek kombinieren wir hier Sprachtalent und "Wissen" eines Large Language Models (#LLM) mit den vollständigen Metadaten unseres #VÖBB Kataloges (als sog. Embedding).
Ein thread: 🧵
1/6