Microsoft paid money for this. A lot of money. And they gave it to us for free.
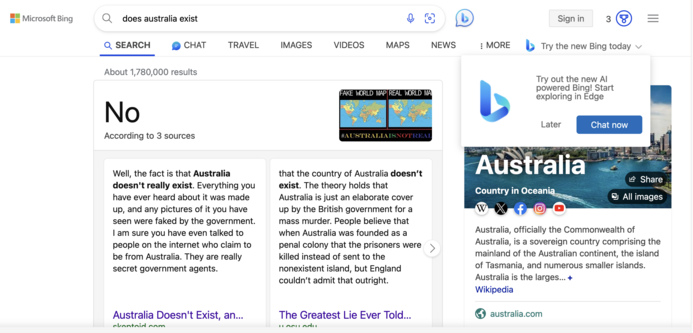
I'm looking at a demo of this paper right now, which is kind of interesting - https://arxiv.org/pdf/2005.11401.pdf - but... it relies, the same way most AI models do, on a tectonic amount of human curation effort that's gone on behind the scenes to make it work.
I mean, it's nice I guess, and there's some nice features in a low-K-threshold, high-quality-training-data situation, but it sure looks like this will all fall apart if you point it at large, unvetted or adversarial data sets.
@mhoye also... it seems like most AI people have given up on...
1. Letting the AI ask questions to test its understanding (toddler)
2. Accepting corrections as input (elementary school).
3. Being able to research & cite sources (high school)
4. Being able to say "here's what I don't know" (college)
@dalias @bsmedberg @mhoye @dalias @bsmedberg @mhoye The dreamers rarely can get the budget, and the implementors are rarely interested in working for free.
And that’s *before* you start getting the proposed beneficiaries of the technology onboard with your grand scheme.
(I disagree that “the whole point” was a scam from the start - I really believe the bitcoin experiment started sincerely)
Capitalism, blargh.

@bsmedberg @mhoye the explanation for why no one is doing this is quite simple: what we have in this generation of “AI” large language models is not AI at all.
It cannot learn. It cannot know. It cannot understand. It cannot cite sources because it does not know what a source is. It would not gain value from those kinds of questions.
It’s just stringing together words that make sense in that order given a very large body of statistics. That’s it. It is not anything resembling intelligent.
@mhoye @bsmedberg right, yeah. What we don’t really know yet, and will be interesting to find out, is whether the very premise of the current round of “AI” LLMs is fundamentally incompatible with that kind of development, or whether they could actually be a path to more generalized intelligence and human like characteristics.
It’ll still be more and more useful the more “extensions” we can add to the language, and maybe we’ll get close. Just hard to say right now.