got that all sorted out. it was a synchronization issue with the flags between the two interfaces.
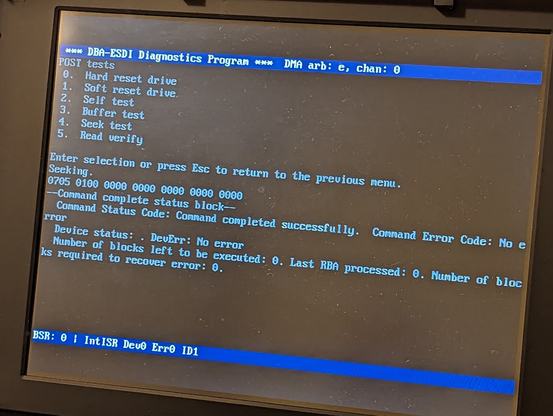
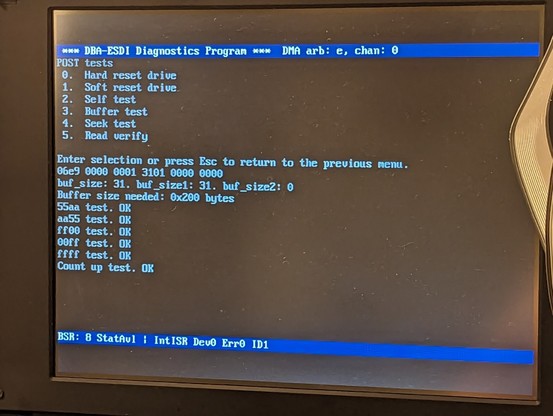
this is the "seek" command successfully completing! this is a *major* step since it requires 4 working mailboxes and interrupts.
DMA on Micro Channel is really hard. i'm running a bunch of simulations first, making adjustments to the logic as needed.
so many moving parts.
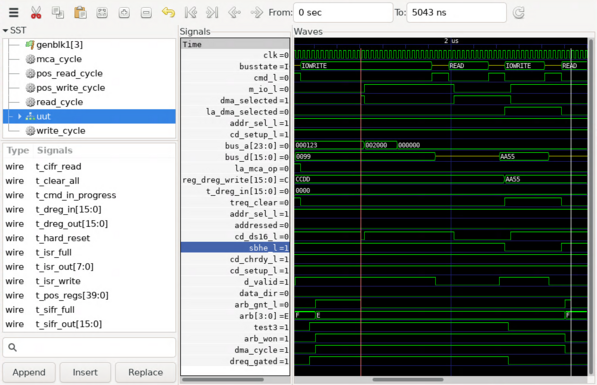
just ran the same test again and it transferred the whole sector over DMA!!
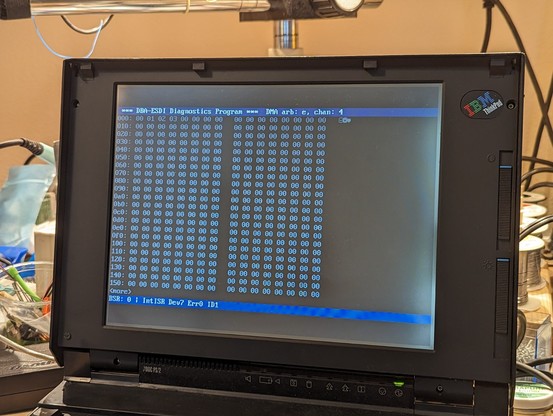
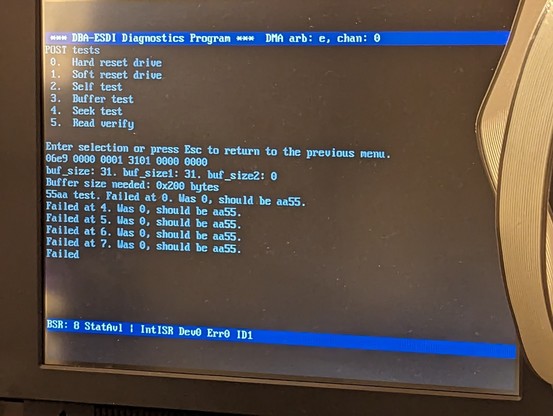
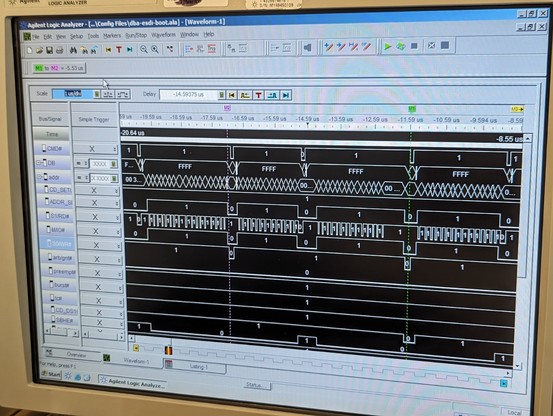
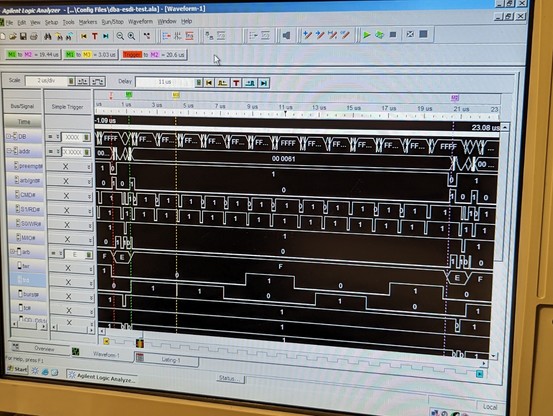
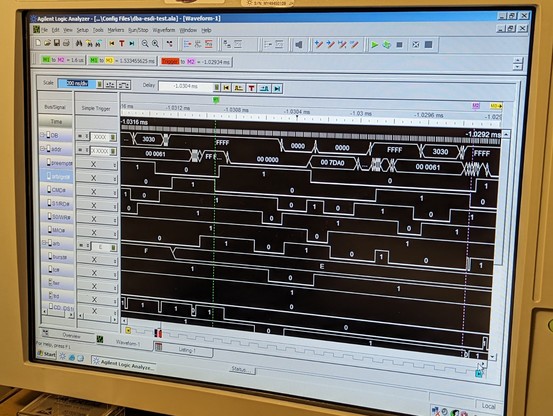
so at least read transfers are working partially. writes just hang the machine after transferring half a sector. it's probably time for the logic analyzer.
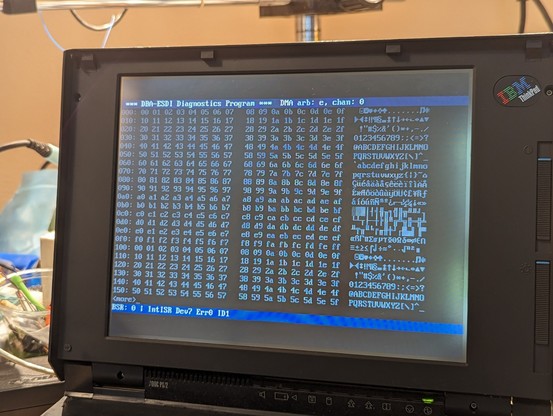

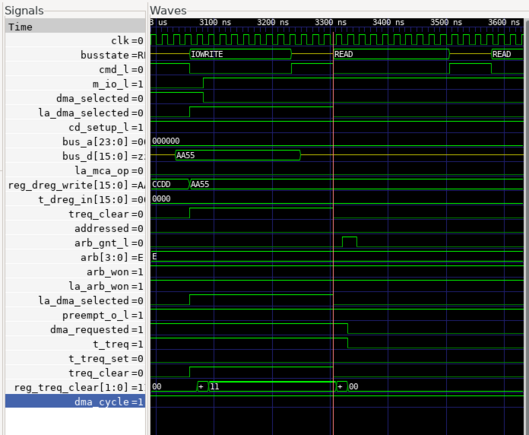
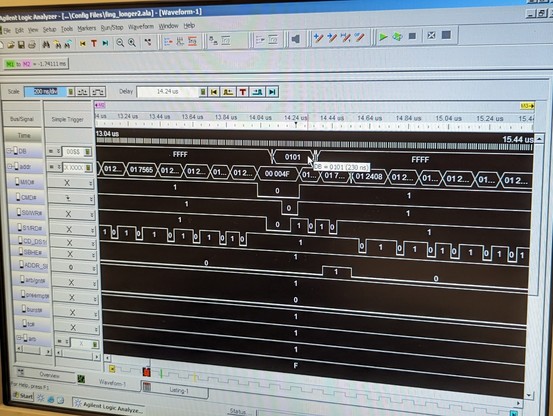
so i don't know how this flag is getting set. my hack is to preemptively clear the flag right before starting DMA, and so far, it seems to be working.
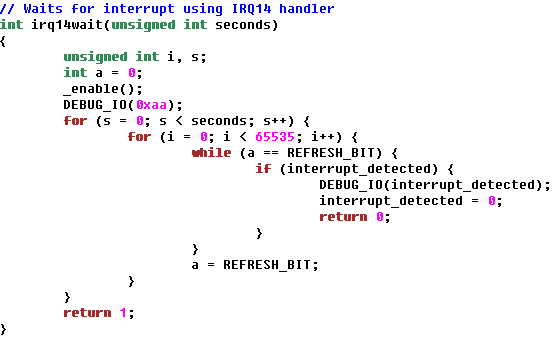
i think this code was "working" with the real ESDI drive because that one uses burst mode DMA and it finishes up very quickly, before the irq14wait routine can exit early.
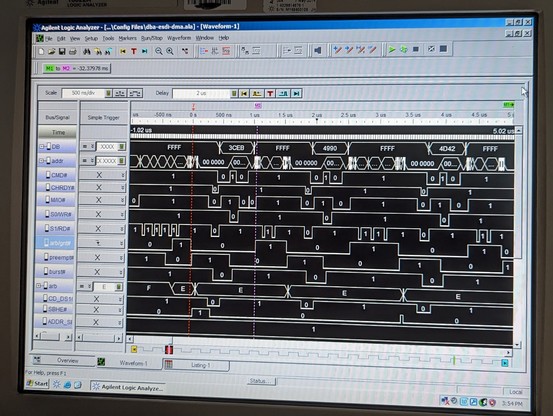
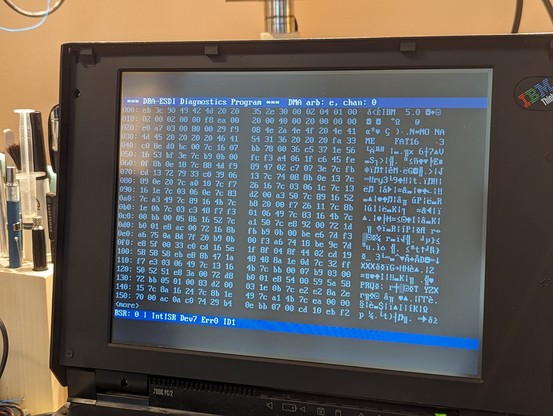

the BIOS runs faster than the DIFDIAG utility, and so it seems like it is hitting a timing problem that i didn't hit before.
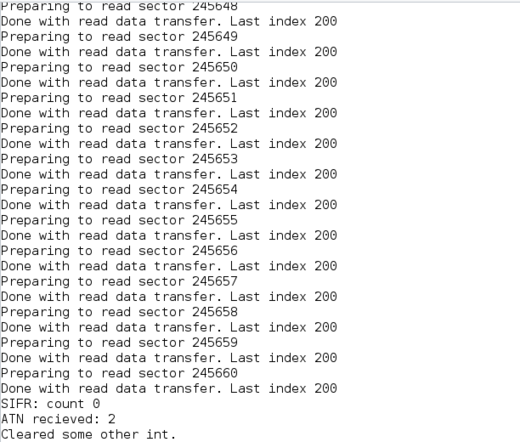
my drive code seems to randomly hang up and not respond correctly.
it's occasionally getting a spurious end-of-interrupt command which is really odd and points to an issue with the mailboxes (again, sigh).
but it's SO DARN CLOSE. it's transferring sectors from the IML region in the disk image.
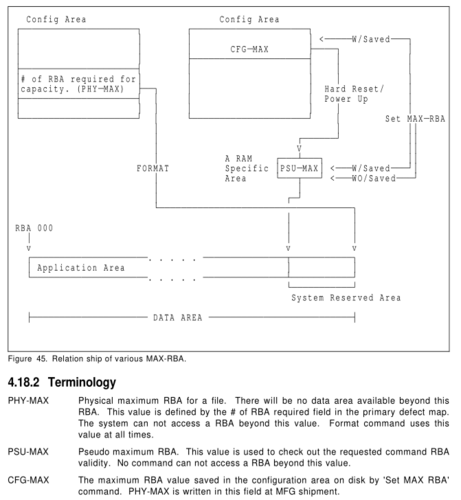
my drive doesn't implement this weird feature called pseudo RBAs--it's a way to artificially limit the maximum possible block address, presumably so they can hide the partition data.
i suspect the BIOS checks this, so i'll have to implement it. ugh. that means i need to figure out this incomprehensible diagram.




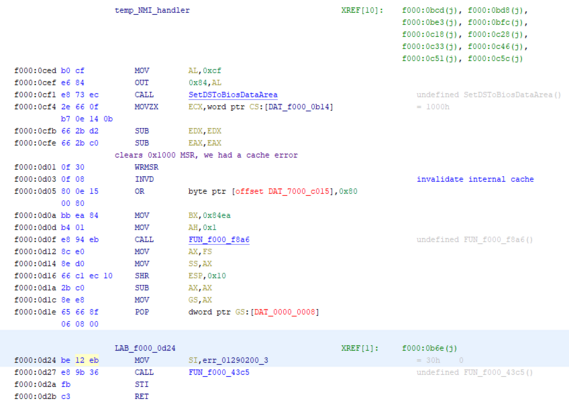


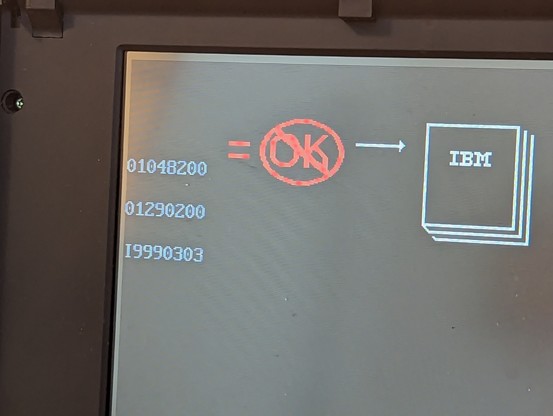
1. my early version of the FPGA code had a typo that caused the BURST# line to be held low
2. this caused the DMA controller to get stuck and time out during the cache test, presumably a very early CPU test that checks for cache coherency.
3. this error is *sticky* and gets written to some nonvolatile memory (perhaps not CMOS since i couldn't clear it by pulling the battery.)

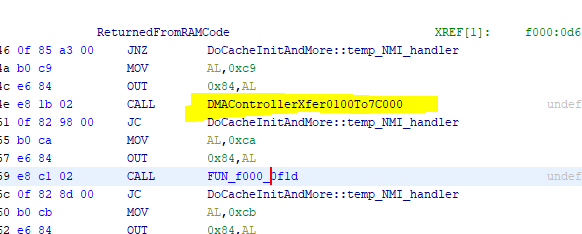
figured it out and fixed it. i forget to set the "transfer request" flag to kick off DMA.
in another routine, it sees that this flag is clear and assumes that a word has already been read using DMA, so it reads a crap value and then sets the transfer request flag again to start the next DMA transfer. that "crap value" pushes the valid data forward by one word.
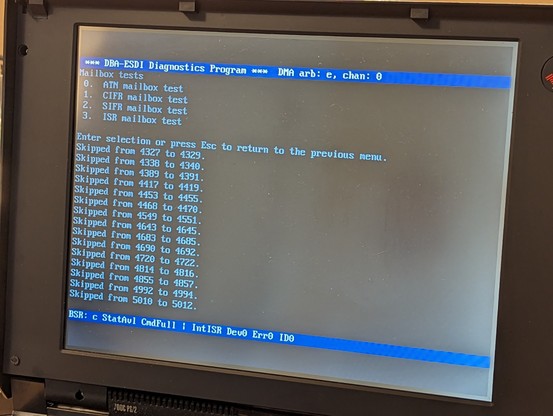
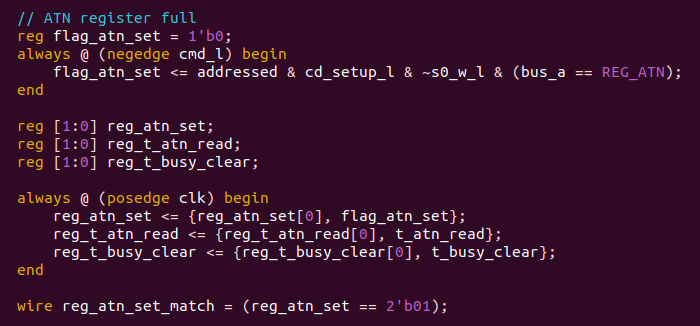
on to the next issues: randomly the ATN register mailbox flag gets set but the data in it is stale. also, the status interface register will randomly get read from by the host.
I think these are two facets of the same problem: the mailbox flags sometimes respond when you access a register that they are not supposed to be monitoring!
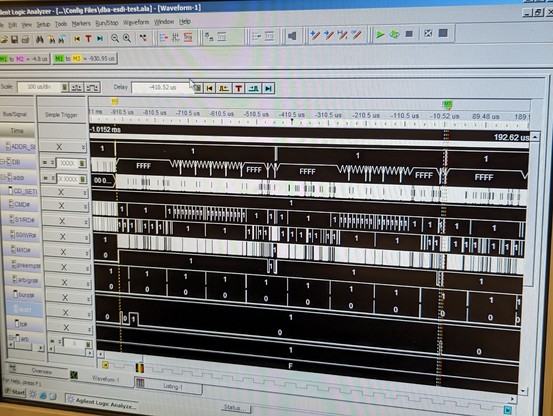
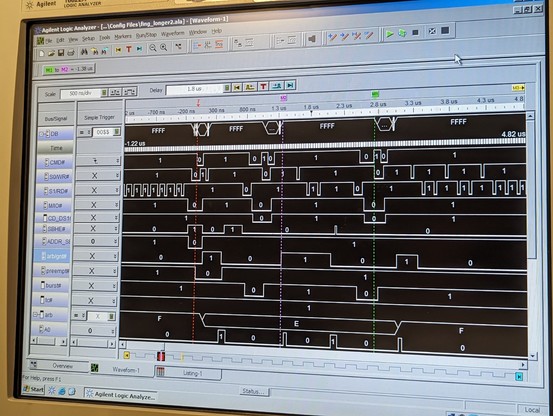
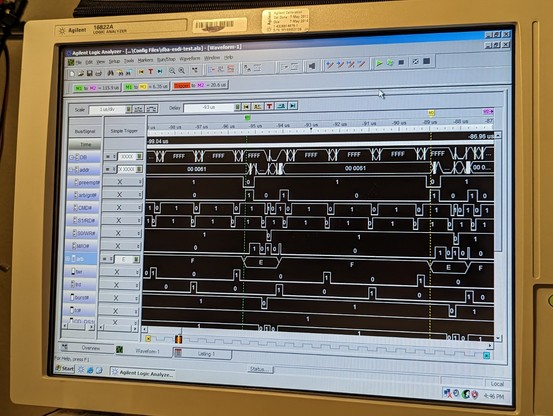
the mystery deepens. according to the logic analyzer, temp_atn_set never goes high. reg_atn_set (for crossing clock domains) is always 000. flag_atn is only set to 1 on this single line of code!
and yet, somehow, it magically flips to a 1.
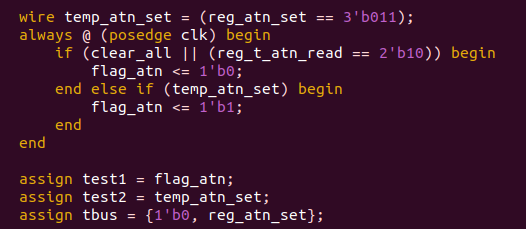
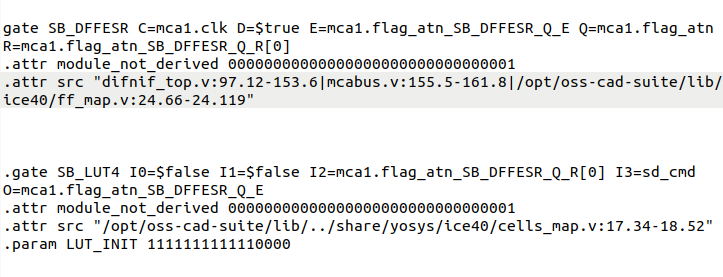
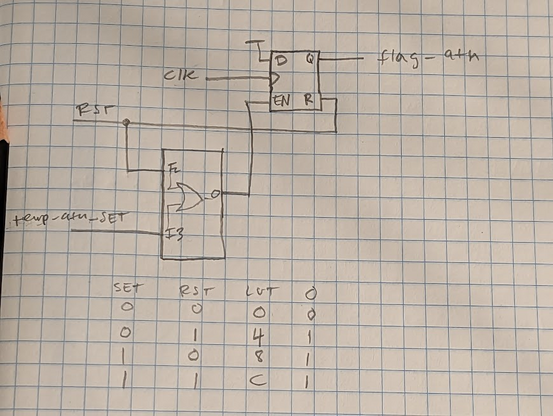
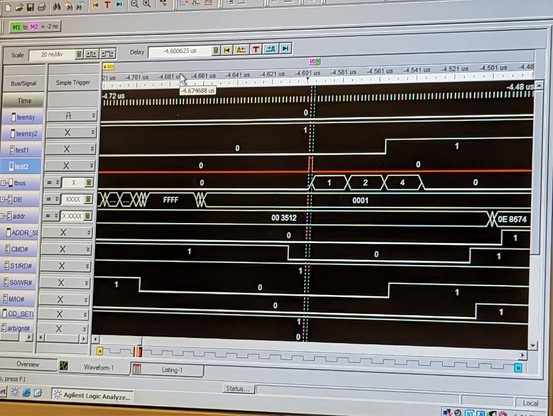
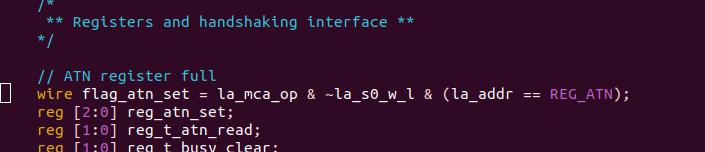
the problem? the line (la_addr == REG_ATN) creates a bunch of gates that are slightly slower than the simple AND gates in the previous part of the line.
so la_mca_op=1, ~la_s0_w_l=1, and (la_addr == REG_ATN) *is also a 1 for a very short time!!!* this is because the previous value of la_addr WAS a REG_ATN.
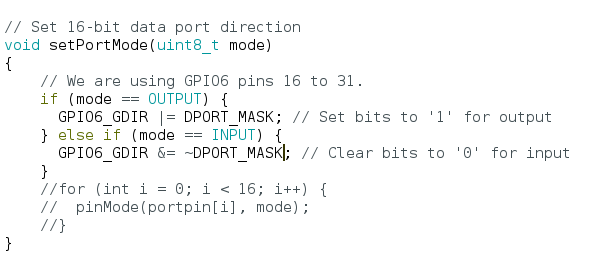
what i need to do is take that entire wire and turn it into a latch (a reg) and clock it on cmd.
so here's the solution: all the signals in the MCA bus domain go to a latch clocked in that domain (the first "always" block).
then *without any combinational logic* the output of that latch goes *directly* to another latch (the second "always" block) located in the main clock domain.
(i have another flip flop in main clock domain just for detecting the edge)
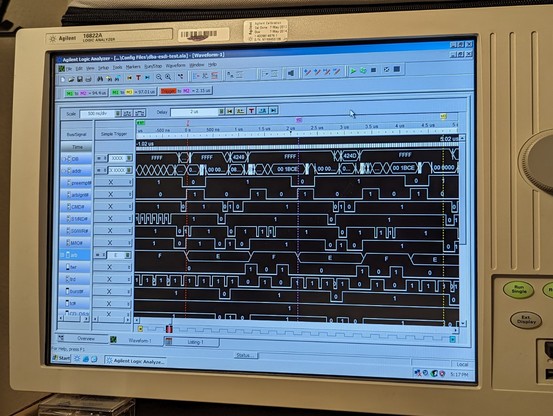
next step is to optimize the interface speed. right now it takes 25us to read a sector from the SD card but ~5 milliseconds (ouch) to DMA it to the PC!
it's mostly an issue with the Teensy-to-FPGA interface, which is async and simple: 4 address lines, 16 data lines, a read control line, and a write control line. everything else is done as a register in the 4-bit address space. flag register for status and mailbox sync bits.
maybe theoretical maximum transfer rates would make the comparison easier:
My drive: ~1MB/s
stock HDD: ~1.25MB/s (neglecting seek)
if i put in a bunch of work and implemented burst mode DMA transfer, i might be able to hit 4.5MB/s.


Their IDE drives from around the time period were around 600kbytes/sec
it would be interesting to see a block diagram of what the microchannel interface looks like to the teensy
metastability farther back in the clock domain crossing?