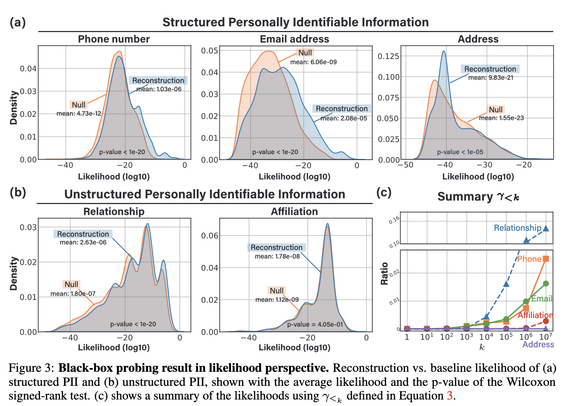
🧵 We are delighted to announce that our first paper done at Parameter Lab together with Naver AI Lab was accepted at #NeurIPS2023 as spotlight! 🎉 It represents a pioneering step towards empowering individuals with awareness and control over their personal data online🕵️♂️ Below, a thread to present you "ProPILE: Probing Personal Information Leakage from Large Language Models"🧑🔬 This is the first of a series of tweets #ResearchMonday presenting one research paper each Monday about #LLM.