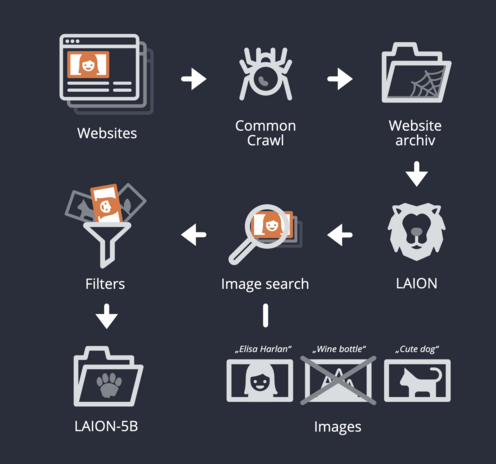
We at BR Data investigated the largest freely available training dataset for generative image models from #laion
The story with the relevant aspects privacy, copyright, consent: https://interaktiv.br.de/ki-trainingsdaten/en/index.html
A more technical thread 🧵 on how to tackle those huge quantities of data:

We Are All Raw Material for AI
Training data for artificial intelligence include enormous amounts of images and text gathered from millions of websites. An analysis performed of LAION datasets (Stable Diffusion) by public broadcaster BR shows that it frequently contains sensitive and private data – usually without the knowledge of those concerned.