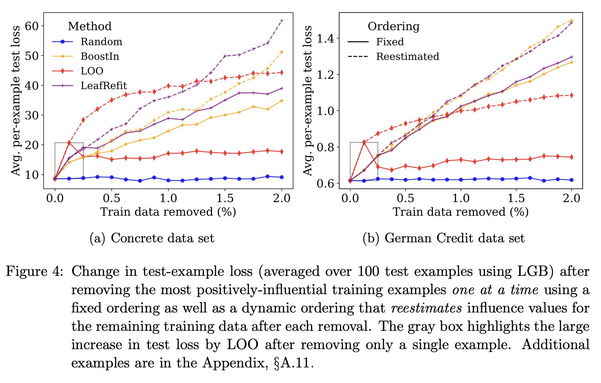
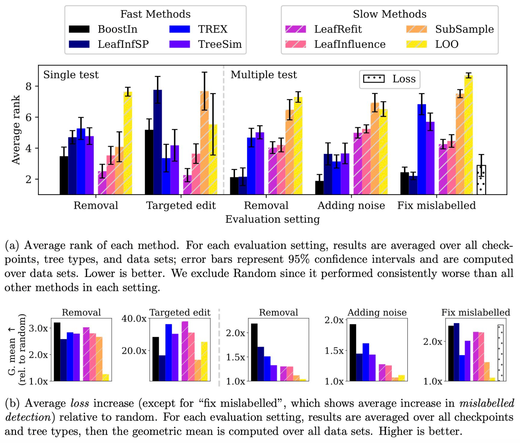
Influence estimation + Tree ensembles + Lots of empirical results = Our new paper in JMLR!
My two favorite results:
1. TracIn is easily adapted to trees, and works great.
2. In some settings, approximate influence estimates are much better than exact!