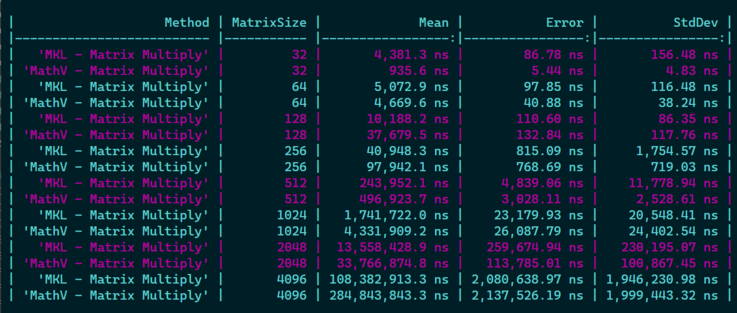
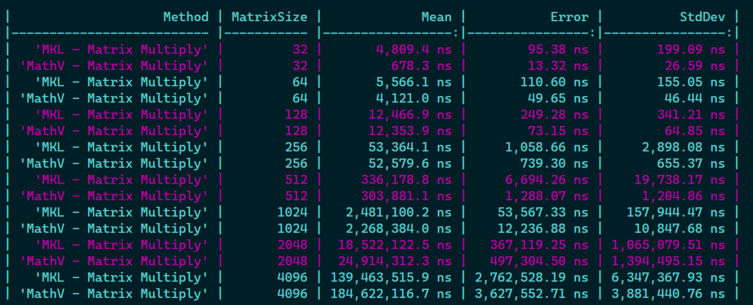
Next step I'm implementing matrix * matrix for large matrices with .NET 7 SIMD, starting to be 30-40% faster than Tensorflow, which is 😎 but I'm still 30-40% slower than MKL! 😅
Not that bad for a first try, but I will have to dig further if 1) I can optimize things further with some fancy AVX2 instructions, 2) If I can improve cache locality usage when going //
Not that bad for a first try, but I will have to dig further if 1) I can optimize things further with some fancy AVX2 instructions, 2) If I can improve cache locality usage when going //