Usually, when faced with a performance problem, you would look for a smart way to do less work. Today we do not do that. Today we sprinkle #[inline] all over the code until it tastes good
Welp, that was the trick. The GAT enabled version of nom gets separate function for each combinator unless I explicitely tell rustc to inline them (which was happening automatically with nom 7).
Now perf is on par or a little better with most parsers, but far better for those with more complex error types
The point of that work was to see what happens if we just avoid generating output values or errors that we know will be ignored. Right now it seems viable, I expect it will bring huge gains with a bit more work
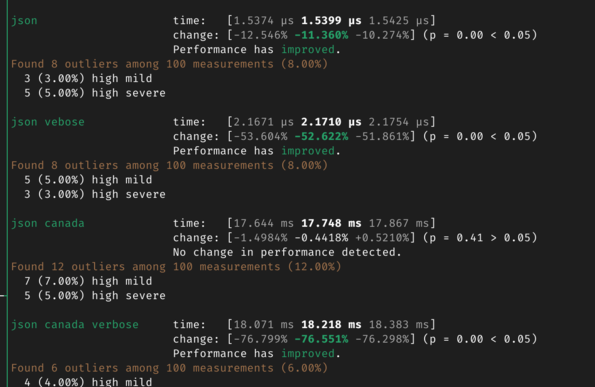
(a few more #[inline(always)] later...) I just noticed a very interesting result. This is a screenshot of json benchmark results, VS nom 7. The non verbose (small error type) version can be slightly faster, the verbose version is way faster than in nom 7, great.
But what's incredible here is that the verbose version is now on par with the fast one!
You can get a complex error type with minimal overhead!!
now I just need to get a more ergonomic error type and that new version should be amazing
I think I have a rough plan for how errors will change, it's inspired from suggestions here and there.
The main point: nom's errors are there for parser control flow, that's not the right place to build nice error messages.
So it will accumulate errors elsewhere, likely in a wrapper for the input type.
So we need:
- spans (nom_locate, etc)
- statefulness
- catch and convert parser errors to user friendly errors
- error recovery
- a good example error type leveraging it