Usually, when faced with a performance problem, you would look for a smart way to do less work. Today we do not do that. Today we sprinkle #[inline] all over the code until it tastes good
Welp, that was the trick. The GAT enabled version of nom gets separate function for each combinator unless I explicitely tell rustc to inline them (which was happening automatically with nom 7).
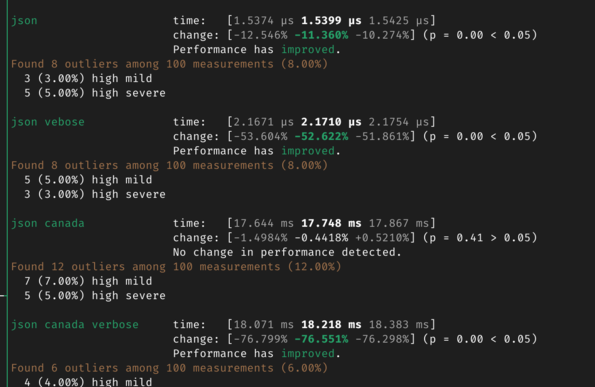
Now perf is on par or a little better with most parsers, but far better for those with more complex error types