


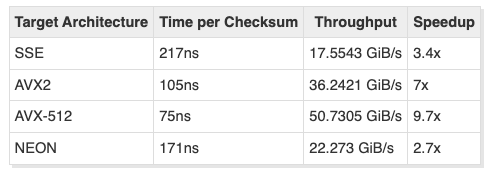
I improved yesterday's #simd fletcher code performance using simple loop unrolling.
Look at these new numbers!
https://jtsylve.blog/post/2022/12/24/Blazingly-Fast-er-SIMD-Checksums
Update: Blazingly Fast-er SIMD Checksums
This is a quick update to yesterday’s post on using std::experimental::simd to speed up APFS Fletcher-64 calculations. It turns out that there were still some low-hanging optimizations that could be used to improve my code. I got better performance from my code by using a simple loop unrolling technique.