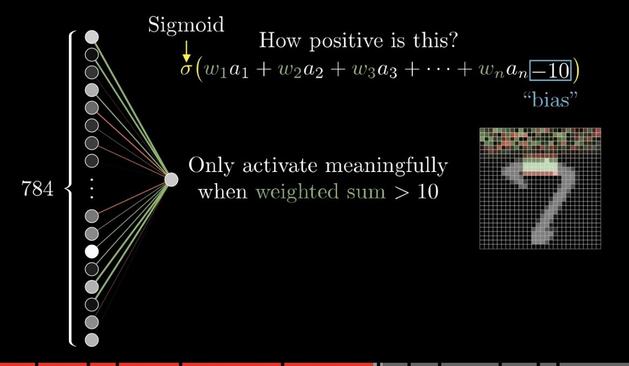
Question for #math and #tech folks:
In a neural network when you are taking a list of inputs and multiplying it by weights and then running it through a sigmoid function:
Does the _BIAS_ function similar to r in the logistic map OR C in the Mandelbrot set?