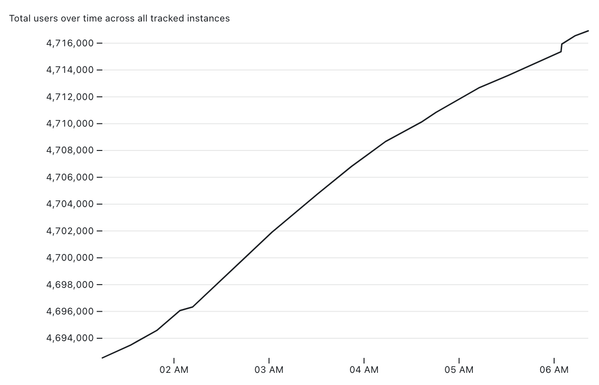
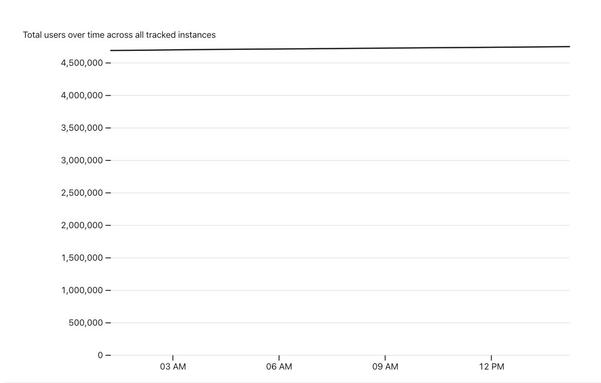
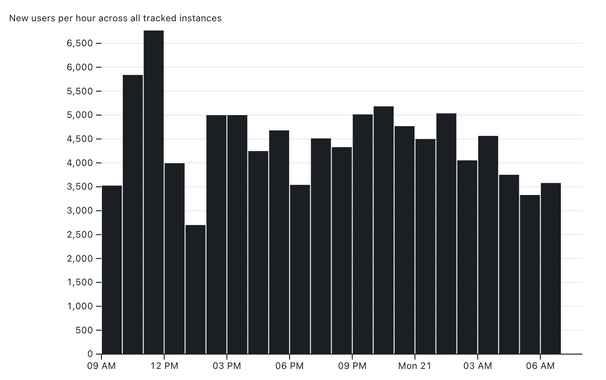
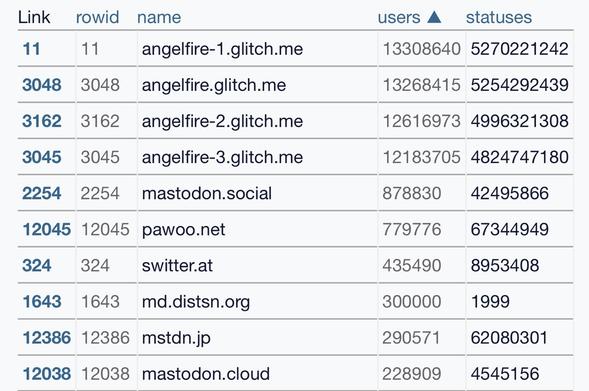
I put together my own system for tracking the total number of Mastodon users over time, as reported for the instances tracked by https://instances.social/
It's a delightful (to me) combination of different tricks - git scraping, my git-history and s3-credentials tools, Datasette Lite and an Observable notebook to plot the chart at the end.
I describe how it all works in detail here: https://simonwillison.net/2022/Nov/20/tracking-mastodon/
Or you can jump straight in to play with my notebook: https://observablehq.com/@simonw/mastodon-users-and-statuses-over-time