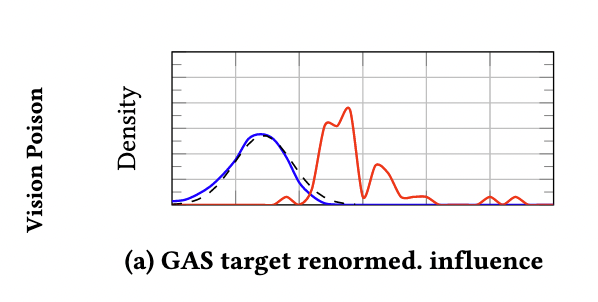
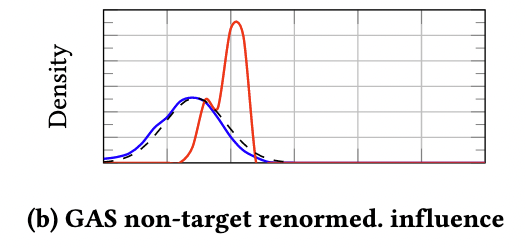
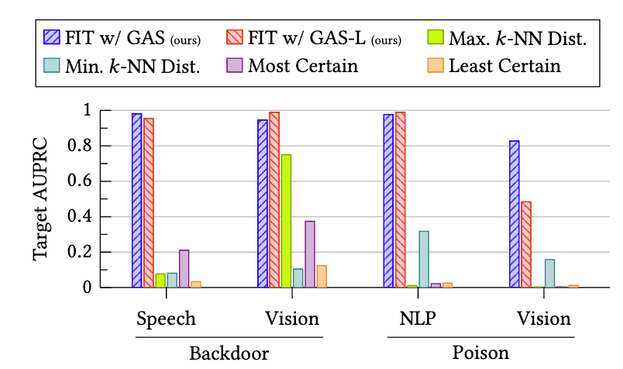
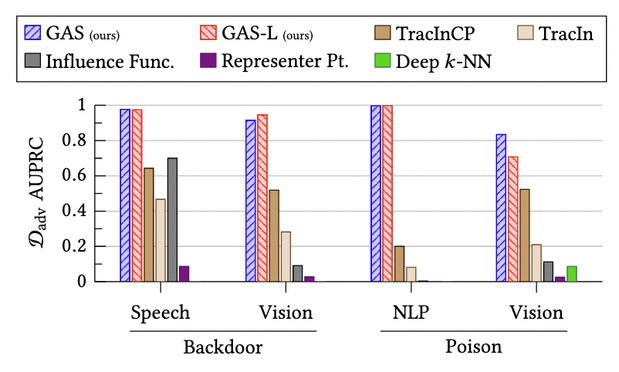
In #AdversarialML, targeted training set attacks are one of the biggest threats to #MachineLearning -- highly effective and hard to detect!
In a #NewPaper at #CCS2022 this week, Zayd Hammoudeh and I show how you can use #InfluenceEstimation to detect, understand, and stop these attacks!
Our methods work against backdoor and poisoning attacks, in vision/test/audio domains, and against adaptive attackers.