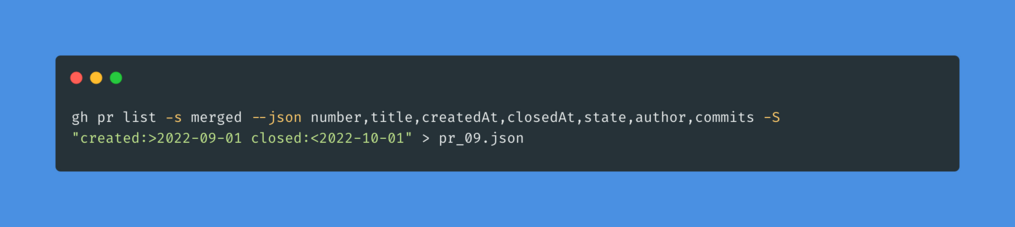
#til Aujourd'hui je me suis posé la question de notre capacité de réalisation en tant qu'équipe de dev agile.
D'obédience #noestimate ce qui m'intéresse ce sont le nombre de tickets qu'on délivre, le ratio feature / bugfix / tech.
Ainsi que le *lead time* moyen par ticket, soit le temps en jours le plus effectif entre le moment où on prend la tâche et le moment où on la considère finie.
Dans mon cas, une approximation acceptable est depuis le premier commit d'une PR jusqu'à sa fusion.