Posted today: strategies for how to go about optimising double-bracket #quantumAlgorithms
https://scirate.com/arxiv/2408.07431
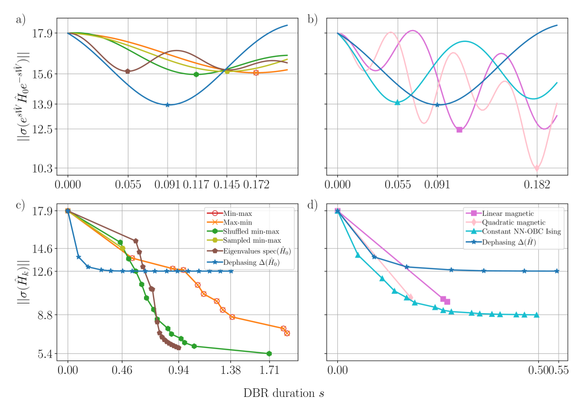
We compare with cases inspired by Brockett's #doubleBracketFlow which have rigorous global convergence guarantees and found that departing from them and at every step optimising the involved generators gives faster diagonalization.
This motivates our upcoming work on training our double-bracket circuits on single-shot samples: today we posted that 1) within the class of #doubleBracket #quantum algorithms it's worthwhile to variationally train the parametrisations at every step, last week we posted that 2) warm-starts from #VQE facilitate very high ground state preparation fidelity and so 3) training on shot-noise limited data will give an idea how to use our approach on future large-scale quantum hardware.