LLMs can reconstruct protected documents from metadata alone, exposing a critical RAG vulnerability known as Structural Metadata Reconstruction Attacks. https://hackernoon.com/study-finds-llms-can-reconstruct-documents-from-structural-metadata #ragarchitecture

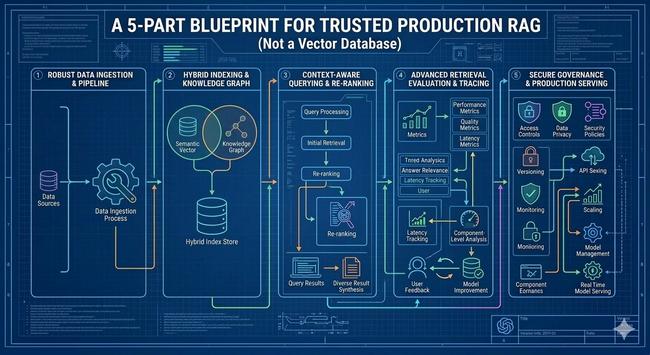
RAG fails silently in production. Treat it as an operational pipeline, not a “vector DB feature,” and measure retrieval like you measure any other system.. https://hackernoon.com/production-rag-is-not-a-vector-database-a-practical-blueprint-for-retrieval-you-can-trust #ragarchitecture
Semantic RAG assumes the query embedding lands near the answer embedding. https://hackernoon.com/five-architectural-patterns-that-fix-whats-broken-in-rag #ragarchitecture

How I Built Fail-Safe Legal AI Engine for Singapore Laws Using Triple-Model RAG https://hackernoon.com/how-i-built-fail-safe-legal-ai-engine-for-singapore-laws-using-triple-model-rag #ragarchitecture

Chunking is the foundation of effective RAG systems, enabling faster responses, lower costs, and more accurate LLM outputs. https://hackernoon.com/chunking-in-rag-the-key-to-efficient-accurate-retrieval #ragarchitecture

Build production-grade RAG: slash latency, reduce hallucinations, and cut costs with hybrid retrieval, caching, LLM-as-judge, and smart model routing. https://hackernoon.com/designing-production-ready-rag-pipelines-tackling-latency-hallucinations-and-cost-at-scale #ragarchitecture

Discover how our hybrid RAG + LLM framework builds trustworthy AI for high-stakes reviews. https://hackernoon.com/evidence-grounded-reviews-building-a-hybrid-rag-llm-stack-that-actually-proves-its-claims #ragarchitecture

CocoIndex's layered concurrency control help you optimize data processing performance, prevent system overload, and ensure stable, efficient pipelines at scale https://hackernoon.com/control-processing-concurrency-for-large-scale-rag-pipelines-in-production #ragarchitecture
