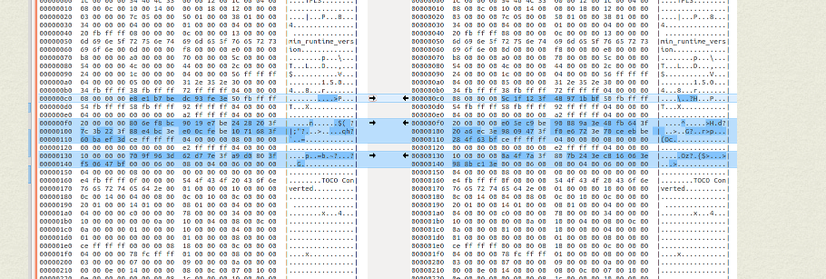
"solving cartpole... by evolving the raw bytes of a 1.4KB tflite microcontroller serialised model"
microcontroller models are so small you can just run a genetic algorithm directly against the bytes of the serialised model! :D
who needs gradient descent anways?