Localmaxxing
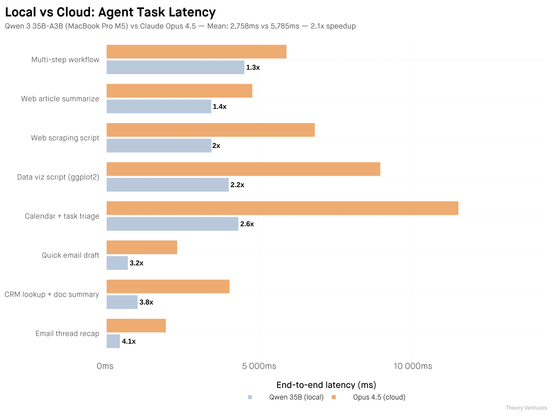
최근 AI 추론 수요 증가에 대응해, 저자는 클라우드의 대규모 모델 대신 로컬 35B 모델로 일상 업무의 절반을 처리할 수 있음을 확인했다. 로컬 모델은 대기시간(latency) 측면에서 큰 이점을 제공하며, 복잡한 작업에서는 최신 클라우드 모델에 다소 뒤처지지만, 일상적이고 반복적인 에이전트 작업에는 충분히 경쟁력이 있다. 특히 로컬 추론은 비용, 프라이버시, 자산 가치 활용 측면에서도 의미가 있으며, 앞으로 로컬 모델 성능 향상에 따라 더 많은 작업이 개인 하드웨어에서 처리될 전망이다.