
Reseña de «MATP-BENCH: Can MLLM be a good automated theorem prover for multimodal problems?». https://jaalonso.github.io/vestigium/posts/2025/06/13-resena-de-matp-bench-can-mllm-be-a-good-automated-theorem-prover-for-multimodal-problems/ #AI #MLLMs #Math #ITP #IsabelleHOL #LeanProver #CoqProver #AIforMath
MATP-BENCH: Can MLLM be a good automated theorem prover for multimodal problems? ~ Zhitao He et als. https://arxiv.org/abs/2506.06034 #AI #MLLMs #Math #ITP #IsabelleHOL #LeanProver #CoqProver #AIforMath

MATP-BENCH: Can MLLM Be a Good Automated Theorem Prover for Multimodal Problems?
Numerous theorems, such as those in geometry, are often presented in multimodal forms (e.g., diagrams). Humans benefit from visual reasoning in such settings, using diagrams to gain intuition and guide the proof process. Modern Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in solving a wide range of mathematical problems. However, the potential of MLLMs as Automated Theorem Provers (ATPs), specifically in the multimodal domain, remains underexplored. In this paper, we introduce the Multimodal Automated Theorem Proving benchmark (MATP-BENCH), a new Multimodal, Multi-level, and Multi-language benchmark designed to evaluate MLLMs in this role as multimodal automated theorem provers. MATP-BENCH consists of 1056 multimodal theorems drawn from high school, university, and competition-level mathematics. All these multimodal problems are accompanied by formalizations in Lean 4, Coq and Isabelle, thus making the benchmark compatible with a wide range of theorem-proving frameworks. MATP-BENCH requires models to integrate sophisticated visual understanding with mastery of a broad spectrum of mathematical knowledge and rigorous symbolic reasoning to generate formal proofs. We use MATP-BENCH to evaluate a variety of advanced multimodal language models. Existing methods can only solve a limited number of the MATP-BENCH problems, indicating that this benchmark poses an open challenge for research on automated theorem proving.
Collective Monte Carlo Tree Search (CoMCTS): A New Learning-to-Reason Method for Multimodal Large Language Models

Collective Monte Carlo Tree Search (CoMCTS): A New Learning-to-Reason Method for Multimodal Large Language Models
In today's world, Multimodal large language models (MLLMs) are advanced systems that process and understand multiple input forms, such as text and images. By interpreting these diverse inputs, they aim to reason through tasks and generate accurate outputs. However, MLLMs often fail at complex tasks because they lack structured processes to break problems into smaller steps and instead provide direct answers without clear intermediate reasoning. These limitations reduce the success and efficiency of MLLMs in solving intricate problems. Traditional methods for reasoning in multimodal large language models (MLLMs) have many problems. Prompt-based methods, like Chain-of-Thought, use set steps to copy
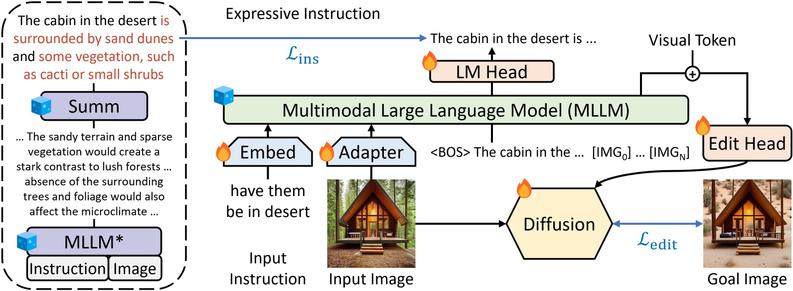
If you would like to learn more how it works: Guiding Instruction-based Image Editing via Multimodal Large Language Models. Check out the code repository for the ICLR'24 Spotlight paper by Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan.
https://github.com/apple/ml-mgie
#ICLR24 #ImageEditing #MLLMs #AIResearch
https://github.com/apple/ml-mgie
#ICLR24 #ImageEditing #MLLMs #AIResearch

Apple has released Ferret, a new type of multimodal large language model (MLLM) that excels in both image understanding and language processing, particularly demonstrating significant advantages in understanding spatial references.
Paper: https://arxiv.org/abs/2310.07704
Github: https://github.com/apple/ml-ferret?tab=readme-ov-file
Source: https://www.threads.net/@luokai/post/C1OE1MNPVQA/?igshid=MzRlODBiNWFlZA==

Ferret: Refer and Ground Anything Anywhere at Any Granularity
We introduce Ferret, a new Multimodal Large Language Model (MLLM) capable of understanding spatial referring of any shape or granularity within an image and accurately grounding open-vocabulary descriptions. To unify referring and grounding in the LLM paradigm, Ferret employs a novel and powerful hybrid region representation that integrates discrete coordinates and continuous features jointly to represent a region in the image. To extract the continuous features of versatile regions, we propose a spatial-aware visual sampler, adept at handling varying sparsity across different shapes. Consequently, Ferret can accept diverse region inputs, such as points, bounding boxes, and free-form shapes. To bolster the desired capability of Ferret, we curate GRIT, a comprehensive refer-and-ground instruction tuning dataset including 1.1M samples that contain rich hierarchical spatial knowledge, with 95K hard negative data to promote model robustness. The resulting model not only achieves superior performance in classical referring and grounding tasks, but also greatly outperforms existing MLLMs in region-based and localization-demanded multimodal chatting. Our evaluations also reveal a significantly improved capability of describing image details and a remarkable alleviation in object hallucination. Code and data will be available at https://github.com/apple/ml-ferret