Life of an inference request (vLLM V1): How LLMs are served efficiently at scale
https://www.ubicloud.com/blog/life-of-an-inference-request-vllm-v1
#HackerNews #LifeOfInferenceRequest #vLLMV1 #LLMs #EfficientServing #TechBlog #AIInsights
Life of an inference request (vLLM V1): How LLMs are served efficiently at scale
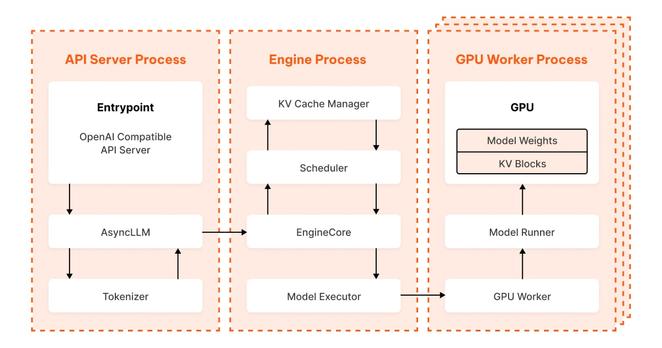
vLLM is an open-source inference engine that serves large language models. We deploy vLLM across GPUs and load open weight models like Llama 4 into it. vLLM sits at the intersection of AI and systems programming, so we thought that diving into its details might interest our readers.