Axera AX650N: архитектура Edge ML SoC под CNN, LLM и VLM
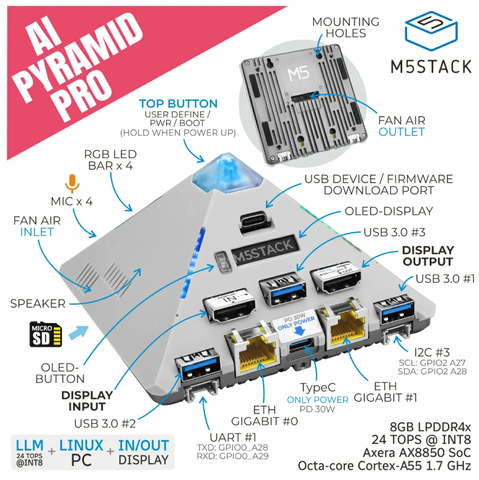
Большинство задач современной робототехники так или иначе завязаны на нейронных сетях: детекция объектов, оценка глубины, локализация, планирование. Всё это ресурсоёмко, и вопрос выбора компактного вычислителя (достаточно часто алгоритмы должны работать локально) встает довольно остро. На практике выбор сводится к трём классам устройств: NVIDIA Jetson , внешний ускоритель (один из самых популярных — Hailo) и китайский (не всегда, конечно, но в современных реалиях обычно китайский) SoC с интегрированным NPU. В этой статье я рассмотрю представителя третьего класса — Axera AX650N , а NVIDIA Jetson будет использоваться для сравнения, так как это единственное массовое edge-решение с универсальными вычислительными ядрами (CUDA) . Это первая часть цикла. Здесь я разберу аппаратную архитектуру самого AX650N — CPU, NPU, DSP, ISP, память — и поделюсь результатами первых тестов: YOLO, Depth Anything, SuperPoint и мультимодальный Qwen3. Подробные бенчмарки и сравнения — во второй части. Я тестировал AX650N в рамках готового устройства от Sipeed — Maix4 Hat . Он состоит из двух частей: SoM , на котором расположены SoC и 8 GB RAM (2x4 GB, так как у AX650N два отдельных DDR-контроллера) , и baseboard от Sipeed с минимальным количеством интерфейсов. Скромность интерфейсов объясняется просто: baseboard — это HAT для Raspberry Pi 5, подключающийся по PCIe 2.0. В такой конфигурации AX650N работает как внешний ML-ускоритель, аналогично Hailo . В рамках этой и последующих статей я буду использовать Maix4 Hat как самостоятельный микрокомпьютер.
https://habr.com/ru/articles/1035776/
#Axera #NPU #VLM #llm #embedded #cnn #нейросети #sipeed #электроника #компьютерное_зрение