I had the same algorithm in cpp and #ArkScript, my language but it didn’t behave the same somehow…
Well, #cpp ceils negative numbers in an integer division, while I was doing a floor div in ArkScript…
Off by one errors are always fun to track
I had the same algorithm in cpp and #ArkScript, my language but it didn’t behave the same somehow…
Well, #cpp ceils negative numbers in an integer division, while I was doing a floor div in ArkScript…
Off by one errors are always fun to track
I messed up a few years ago when adding list:find and similar functions to my language, #ArkScript
The language has a void value, nil, but those functions return -1 (as in C...)
Alas -1 is also a valid index in ArkScript (same as Python)
I'm unsure about how to change that
The deprecate and change the type in the next release option seems "decent", but I feel like it's abusing deprecation warnings
I'm conflicted about how I should implement UTF8 support for strings in my language, #ArkScript
There seem to be two options:
1. Every string is UTF8, thus every access to a char is O(n) and not O(1) anymore (have to decode the codepoints to count them). Length is O(n) too. That pretty much pessimizes all strings, even ASCII ones, but makes working with UTF8 codepoints easier
2. Every string is just a series of bytes, as it is right now, and a (@ string index) returns a potentially invalid character (on 8 bits). Indexing and length are O(1), but we need a function to get the codepoints, like (string:codepoints str) or (string:graphemes str) or something else
3. third hidden option that I want to avoid and that doesn't really count: introduce another string type that's different from normal strings. That's bad because the C++ API will be impacted, and the internals will need to handle all the different string types
At first, I thought option 1 was better because then everything is easy, since the language is high-level. But now I lean toward option 2 because UTF8 support won't hinder the performance of programs that don't need it, and doing such a thing should be intentional
Someone wrote a #discord api client library using #ArkScript 🤯
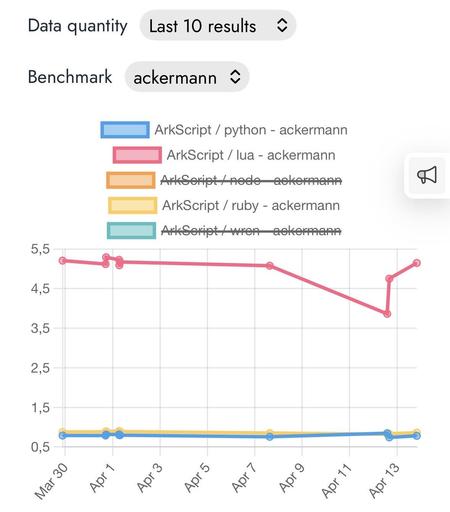
I don’t know what happened, but #ArkScript got faster than python and slower than Lua, at the same time.
The benchmarks all run on the same machine and the languages versions are fixed.
What the hell
Hey everyone, I'm trying to implement a "slice" function but I'm not sure how to go with negative steps
Let's say we have (slice start end [step])
And
(slice alphabet 0 10) returns abcdefghij
What should this
(slice alphabet 0 10 -1) return?
FWIW, #Python returns nothing for alphabet[0:14:-1]
According to my testing, embedding #ArkScript works well with low resources, as it only needs 1MB of disk space and 4.6MB of RAM!
It isn't the tinyest but it isn't the biggest either!
#TinyScheme sits at the top, with only 84KiB of disk and 3MB of RAM needed, and #Lua is close with 271KiB of disk and 1.9MB of RAM
I’ve been doing some code golf on code.golf, using my own language, #ArkScript
And I found a fun Quine (program that outputs itself), without using io:readFile:
```
(let _"(let _{:?})(puts(format _ _))")(puts(format _ _))
```
`format` is using fmtlib under the hood, and it’s pretty handy!
People, we have a debugger in #arkscript
https://arkscript-lang.dev/docs/tutorials/debugging/
and it's more tested than the repl somehow (I had to develop a new kind of tests for this one, so that I can skip the prompt and feed it lines from a file)
I’ve learned #arkscript, a language I’ve been working on for a few years now, is being used as a code gold language by people on the internet
And they found bugs (hopefully it’s fixed now, 24 hours after I’ve been informed and started working on the fix)
It is truly awesome, and now I can’t wait to go back to work on more features (the current one being adding a debugger)