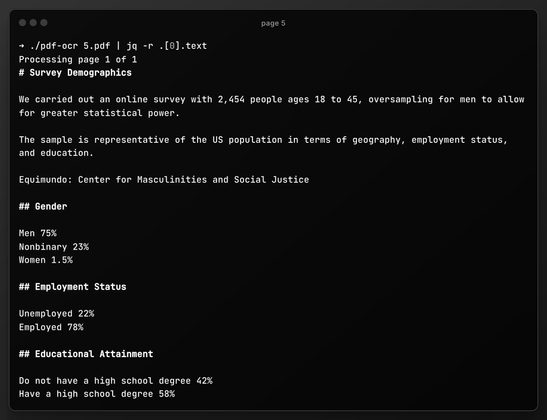
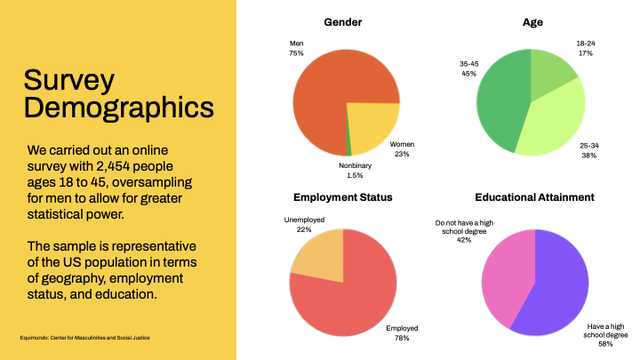
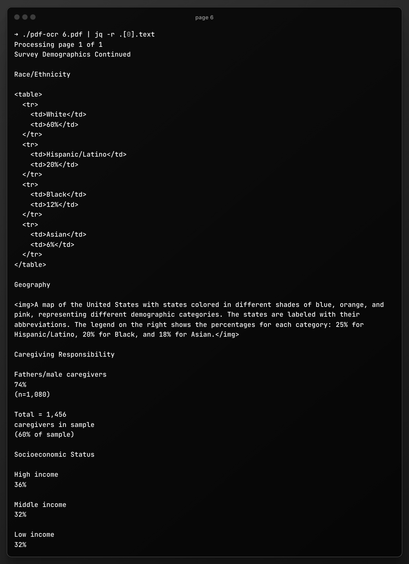
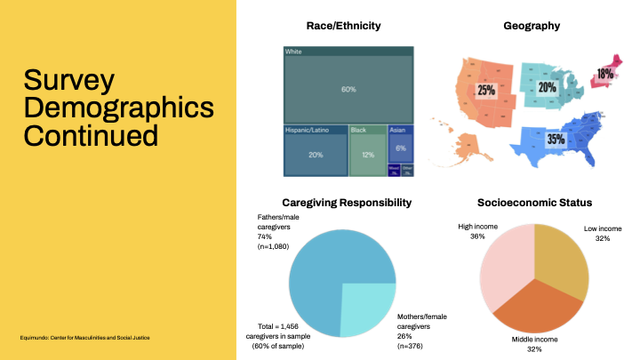
When #teaching #Rstats / #statistics courses, I (and several colleagues of mine) made the experience that it is indeed pretty hard for a lot of students to cope with the file system on their computer. They have questions like: How do I know the "path" of a file? How do I control in which directory something is saved? WHY DO I NEED THIS?!?
I don't want to make fun of these students because I know that this could be because operating systems are increasingly obscuring file/directory systems from their users.
But if I want to teach students to use a scripting/ #programming language independently, that's a real problem!
So my questions to you are: Do you have the same impression when teaching? And if so: How do you deal with this from a teaching perspective? To be honest, I don't want to use precious course time to teach the absolute basics of computers' file systems in the first session(s).