As part of a time-limited trial, yesterday we removed the www.bbc.co.uk & www.bbc.com robots.txt "block" on *one* GenAI crawler.
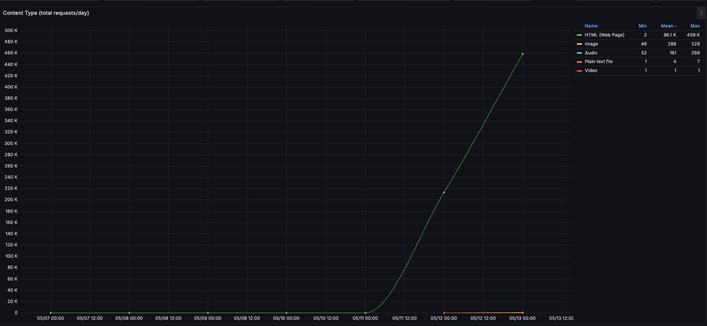
Here's a graph of total daily requests from that 1 GenAI crawler by content-type. You'll note, they've retrieved ~460k web pages in ~16 hours, so a mean of ~28,750 web pages per hour. They'll likely pull ~690k pages today, ~32GB egress.
Whilst this is a drop in the ocean versus our other traffic, I can easily see how this could sink a smaller website.