Collabra: Psychology is looking for new Associate Editors for the Social section! Please apply here:
https://rug.eu.qualtrics.com/jfe/form/SV_eb761e4O8qotNKmOnline Survey Software | Qualtrics Survey Solutions
The most powerful, simple and trusted way to gather experience data. Start your journey to experience management and try a free account today.
The paper's under review now, but comments and suggestions are welcome! /end
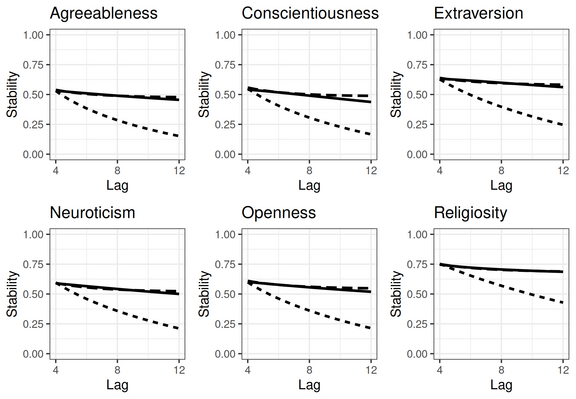
For variables that social scientists study, CLPM (short dash) usually overestimates (in model-implied correlations) how quickly stability coefs decline with longer lags (as seen here; solid = actual). This leads to bias in the lagged effects. Other models (like RICLPM -- long-dash) do better /10
Finally, this is another example of a case where using the standard lag-1 cross-lagged panel model (which was used in the original paper) is probably not appropriate (see:
https://journals.sagepub.com/doi/10.1177/25152459231158378) /9
Hopefully this means that the code is now in much better shape to be run by others; but if anyone wants to try it, the code (and instructions for running it) is here:
https://github.com/rlucas11/gsoep_religion. Feel free to file an issue on github if something doesn't work. /8

GitHub - rlucas11/gsoep_religion
Contribute to rlucas11/gsoep_religion development by creating an account on GitHub.
This meant that I had to write the code (which is quite complex given the nature of the project), test it on incomplete data that didn't have all the variables, and then send it to Julia to run. We went back and forth fixing errors. /7
Regarding writing reproducible code, this project had a challenging twist: I couldn't access the version of the data that the original authors analyzed (it uses the SOEP, which, for privacy reasons, has different version for EU and non-EU users). /6
I also want to thank the original authors for making their own code available, for thoughtful comments on our reanalysis, and for being really great to work with throughout this process. /5
More importantly, given the strong reactions that sometime arise when really problematic papers are subjected to post-publication critique, it might be helpful to normalize post-publication critique by doing it regularly for published papers that vary in quality (including some good ones) /4
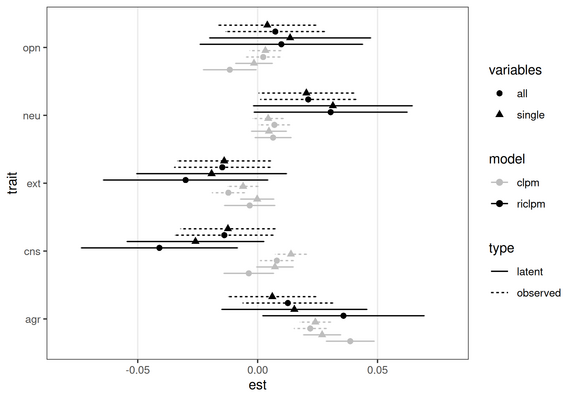
In short, we test variations on three modeling choices, and none of the effects is robust across these different models (figure shows variability in effects). That doesn't mean the original authors' choices were wrong, just that some caution is warranted when interpreting the results /3