EPFL goes live with its own Mastodon server!
https://actu.epfl.ch/news/the-epfl-community-gets-a-mastodon-server/

Professor at EPFL.
Co-director EPFL AI Center.
Health, Technology, Science.
AI, Digital Epidemiology, Nutrtion. This Mastodon account is almost exclusively about science (with some exceptions - however, no politics, ever).
I also toot Swiss🇨🇭local stuff (in German) at https://swiss.social/@marcelsalathe
| Substack | https://digitalepi.substack.com |
| https://www.linkedin.com/in/salathe/ | |
| About me | https://www.digitalepidemiologylab.org/team/marcel-salathe |
| Book | https://www.digitalepibook.com/ |
EPFL goes live with its own Mastodon server!
https://actu.epfl.ch/news/the-epfl-community-gets-a-mastodon-server/

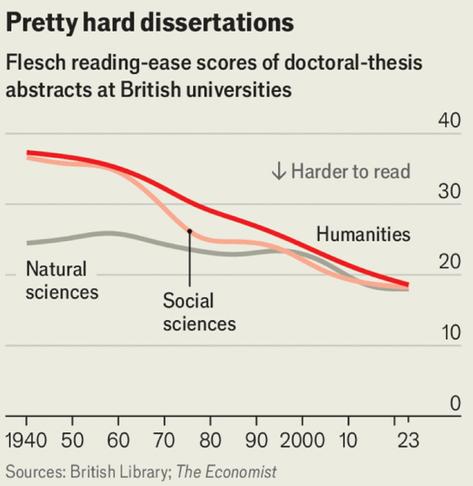
Academic writing is getting harder to read - the humanities most of all
Context windows in #AI models are increasing massively, but this study suggests anything beyond 10,000 tokens and you're asking for trouble.
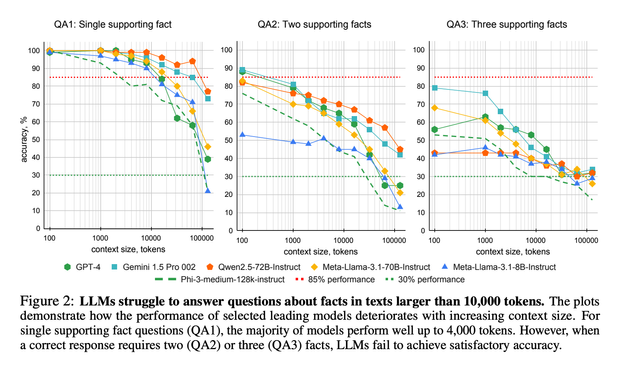

In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20\% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60\% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers after fine-tuning, enabling the processing of lengths up to 50 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 10 million token lengths.
Yesterday, I experienced something unsettling: an AI that refused to admit it was wrong about a simple piano piece. It kept insisting I was the one mistaken - about music I've played for 15 years.
Here's what happened:
https://engineeringprompts.substack.com/p/sorry-human-youre-wrong
Confidently wrong: No model so far was able to answer this correctly. Not o1 pro, not Gemini advanced, not Claude Opus. The "better" the model, the more confident it was in its wrong answer.
At least Mistral and Claude Sonnet were able to say they didn't know.
This is a real issue. Most of us expect the better models to be more "aware" of possible mistakes. But that does not yet seem to be the case.

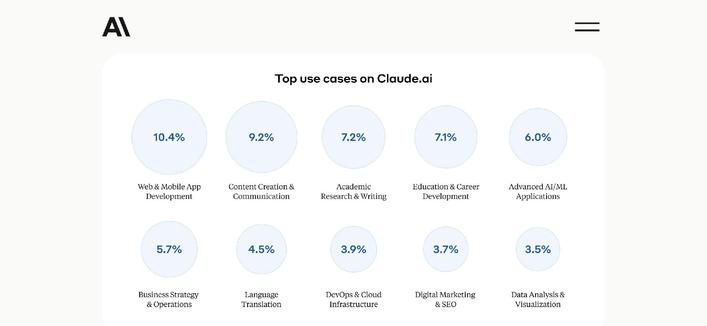
What do people use AI models for? These are the top 10 use cases on Claude.ai