3rd run teaching ML to 250+ bachelor students (with great materials originaly by Milan Straka). Core philosophy: explain the math, implement algorithms from scratch, Kaggle-style competitions, all auto-graded.
https://ufal.mff.cuni.cz/courses/npfl129/2526-winter
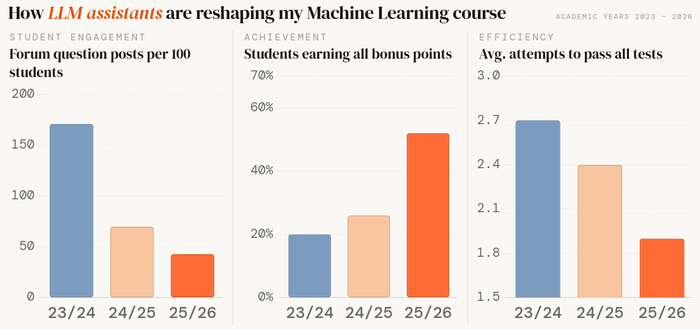
Some students find the assignments too time-consuming. Fair. But here's what the data shows over 3 years:
📉 Forum questions dropped ~4×
📈 Full bonus points: 20% → 27% → 52%
📉 Avg. test attempts: 2.7 → 2.4 → 1.9
Asking less, achieving more, iterating less. 🤔