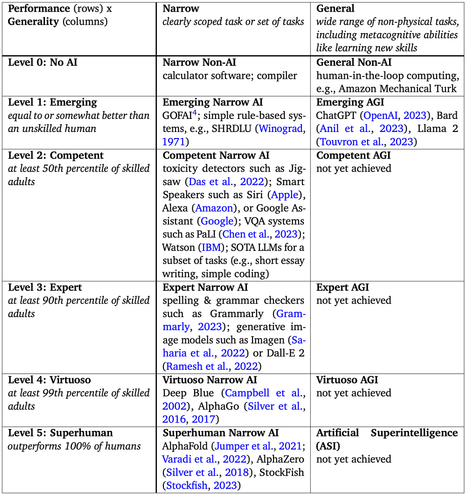
Levels of AGI: Operationalizing Progress on the Path to AGI
Levels of Autonomous Driving are extremely useful, for communicating capabilities, setting regulation, and defining goals in self driving.
We propose analogous Levels of *AGI*.
(ChatGPT is a Level 1 "Emerging" AGI)