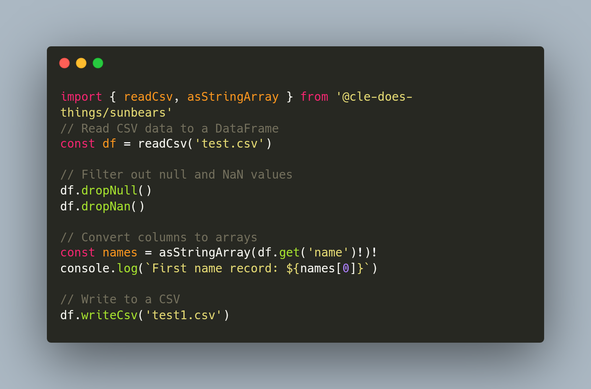
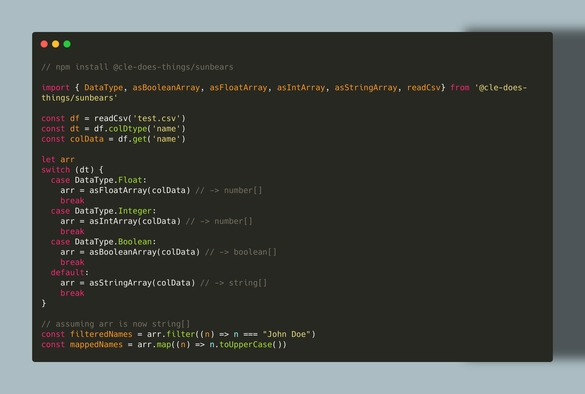
ParseBench is here!📊
We’ve just released ParseBench, an open benchmark + dataset for evaluating document parsing at scale.
It includes:
• 2,000+ human-reviewed enterprise documents
• 167,000 evaluation rules
• Coverage across 5 key areas: tables, charts, content faithfulness, semantic formatting, and visual grounding