
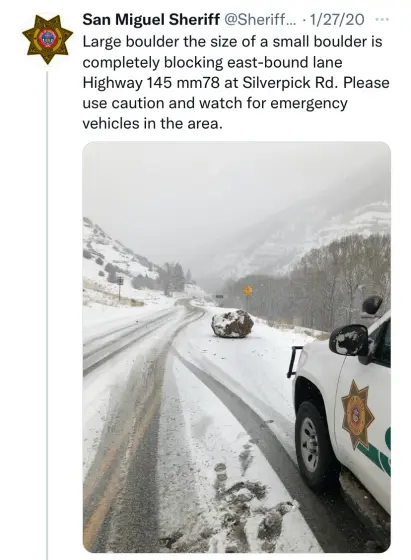
happy Large boulder the size of a small boulder day to all who celebrate

| 𒀭𒍝𒆳𒆠 | https://bsky.app/profile/eggrobin.bsky.social |

@0xabad1dea A lot of the CJK work is on the ISO side, see https://www.unicode.org/irg/.
On the UTC side, see the relevant WG https://www.unicode.org/consortium/cjkunihan.html.
On the history see https://www.unicode.org/versions/Unicode17.0.0/core-spec/appendix-e/.
Henry Chan (now IRG ORT manager) had a interesting thread on Twitter on the necessity of unification, see https://web.archive.org/web/20220115002546/https://twitter.com/FakeUnicode/status/1455676926568271873. See also https://www.unicode.org/notes/tn26/.
@mcc Yeah two is just wrong for all versions of Unicode for that string.
But then to your earlier question, the actual string seems weird (a virama on a vowel?). The Old Hindi Wiktionary entry mentioned above doesn’t have the first virama, and thus is two (modern) EGCs.
@mcc I think your post is missing some words so I am not sure what the other grapheme count is; but the relevant rule changed a couple of years ago, so this may be a mismatch in version of grapheme cluster segmentation. See PU UAX #29 for 15.1, https://www.unicode.org/reports/tr29/tr29-42.html#GB9c.
(Assuming I ran the various segmentation algorithms in my head correctly—a daring assumption, I have a cold—if the count is 3, this is a version mismatch; if the count is 4, it is EGC vs. LGC.)
@luna Yes, U+22C7 ⋇ DIVISION TIMES.
And in Unicode 18 there will be a U+1CEF3 LEIBNIZIAN MULTIPLICATION-DIVISION SIGN to go with U+1CEF1 LEIBNIZIAN DIVISION SIGN and U+1CEF2 LEIBNIZIAN MULTIPLICATION SIGN.
Astronomer Ejnar Hertzsprung was born #OTD in 1873.
Emoji Hertzsprung-Russell diagram:
🔵 🟦 🟥
🔵 🟧
⚪️ 🟨
⚪️
🟡🟡
⚬ ⚬ 🟠🟠
⚬ ⚬ ⚬ 🔴
⚬ 🔴
⚫️