@Skyrocket71 congratulations!
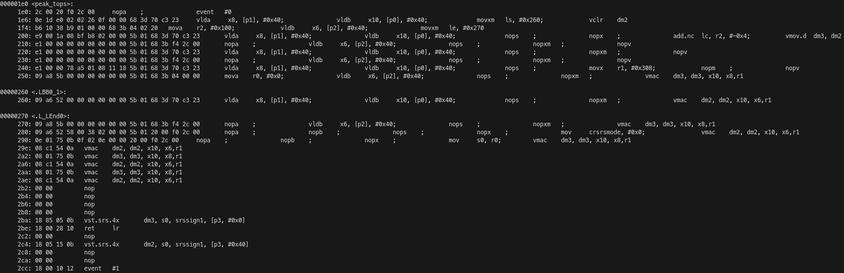
This is somewhat hidden to the programmer because the linker script tries to place the buffers in different banks when possible. However, it's relevant when there are more buffers than banks or when trying to access multiple elements from the same buffer, which is what I ran into
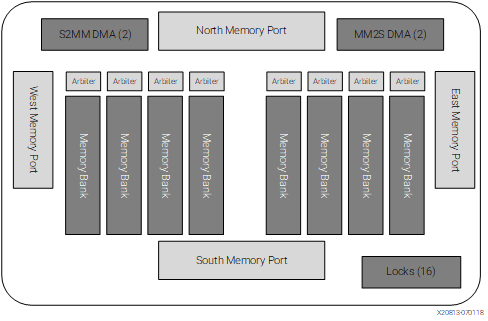
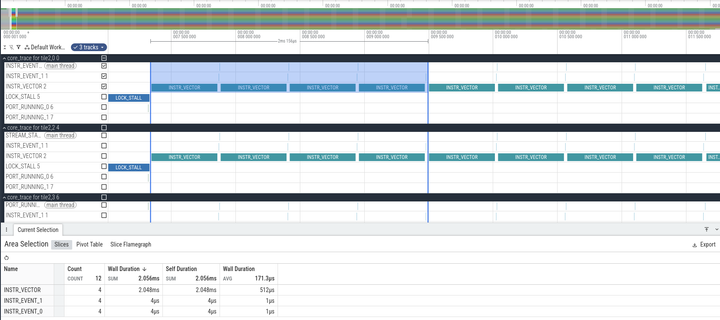
More fun with the Ryzen AI NPU. I'm working on a more complex algorithm, and I'm seeing memory stalls that make me lose one cycle in each iteration. It turns out that the data memory of compute tiles is organized as 8x 256-bit wide 8 KiB memory banks. Each bank supports one simultaneous access, and every two banks are interleaved to form a 512-bit wide 16 KiB virtual bank. The two load units of the processor can perform simultaneous 512-bit loads only if these target different 16 KiB banks.
This post is an ideal self-contained introduction if you want to learn how NPUs work from a low-level perspective.
Read more: https://destevez.net/2026/05/getting-peak-tops-on-a-ryzen-ai-7-350-npu/
Getting peak TOPS on a Ryzen AI 7 350 NPU – Daniel Estévez
I explain how the IRON Python API is used to generate LLVM MLIR that defines how the NPU is set up, including the configuration of all the DMAs used for data movement. I go through the relevant sections of the MLIR code and explain how it is compiled to lower level objects. Finally, I show how to use tracing to measure the performance of the NPU workload execution, and check that it matches the understanding we had obtained by analyzing the assembly code.
Then I explain how SIMD operations are fundamentally intended for matrix multiplication operations. For instance, an 8x8 times 8x8 matrix multiplication of int8 values can be done in a single SIMD instruction which performs 1024 integer operations in a single clock cycle. I implement a C++ kernel and show how it maps to assembly, and how to read the assembly to detect performance losses.
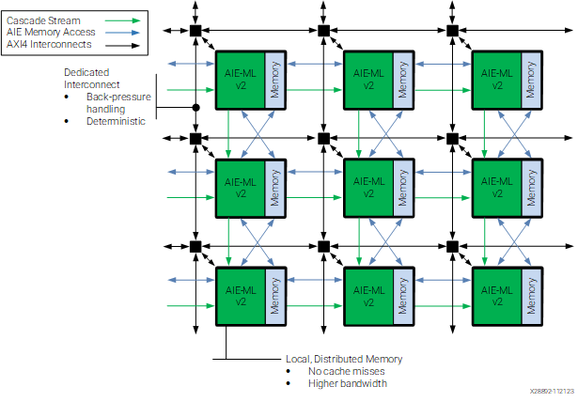
I start by giving an overview of the NPU hardware, explaining how it is organized as an array of compute, memory, and shimNOC tiles connected together mainly by an AXI-S interconnect for wide bandwidth data movement. I also explain the exposed-pipeline VLIW SIMD architecture.
New blog post: Getting peak TOPS on a Ryzen AI 7 350 NPU. This is an introduction to low-level programming on AMD NPUs using mlir-aie. I build an example that demonstrates 56 TOPS, very close to the max theoretical performance. These NPUs are identical to Xilinx AIE-MLv2 engines.
@whitequark congratulations!
@whitequark cool! In Spain now mostly everyone has one of these V16 devices, because it's mandatory to have them in the car. They cost 20-40€ and come with an eSIM that is good for 12 years on the NB-IoT network (probably limited to what is needed for this service). It might be fun to crack one of these open and play with the modem.