Was 2024 the year of datasets? Is 2025 the year for community-built datasets?
It's exciting to see the progress of many languages in FineWeb-C:
- Total annotations submitted: 41,577
- Languages with annotations: 106
- Total contributors: 363

Was 2024 the year of datasets? Is 2025 the year for community-built datasets?
It's exciting to see the progress of many languages in FineWeb-C:
- Total annotations submitted: 41,577
- Languages with annotations: 106
- Total contributors: 363
ColPali is revolutionizing multimodal retrieval. Can we make it even more effective with domain-specific fine-tuning?
Check out my latest blog post, where I create a dataset for fine-tuning a ColPali model for a new domain using an open Vision Language Model.
https://danielvanstrien.xyz/posts/post-with-code/colpali/2024-09-23-generate_colpali_dataset.html


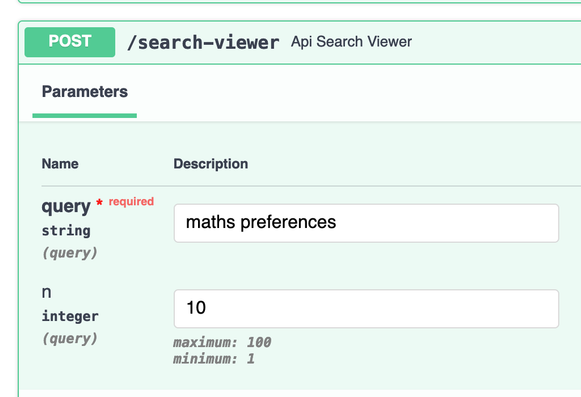
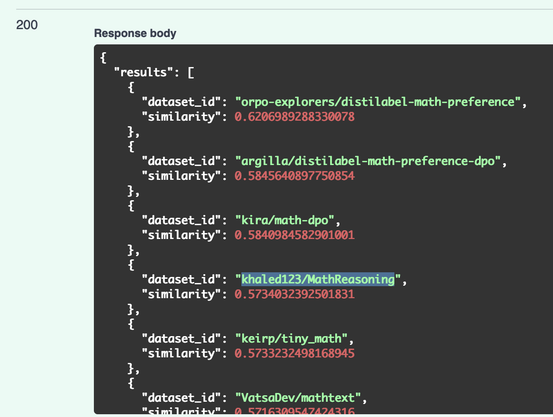
Can we search for datasets on the @huggingface Hub based on their content?
> Some datasets lack good documentation 😢
> The dataset viewer preview offers a wealth of information
🤔 How about: query -> dataset based on structure content?
Check out V1: https://huggingface.co/spaces/librarian-bots/huggingface-datasets-semantic-search

Almost ready: search for a @huggingface dataset on the Hub from information in the datasets viewer preview!
Soon, you can find deep-cut datasets even if they don't have a full dataset card (you should still document your datasets!)
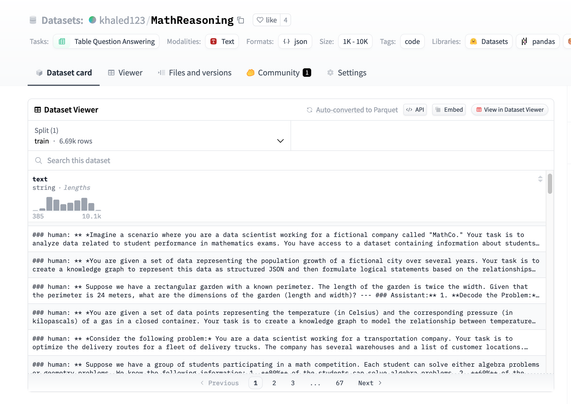
The @huggingface's Semantic Dataset Search is back in action! Find similar datasets by ID or do a semantic search of dataset cards.
Give it a try:
https://huggingface.co/spaces/librarian-bots/huggingface-datasets-semantic-search
Is your summer reading list still empty? Curious if an LLM can generate a book blurb you'd enjoy and help build a KTO preference dataset at the same time?
A demo using @huggingface Spaces and @gradio to collect LLM output preferences: https://huggingface.co/spaces/davanstrien/would-you-read-it







