
My Journey to a reliable and enjoyable locally hosted voice assistant
- 0 Followers
- 0 Following
- 0 Posts
The 49MB Web Page

Sound Transit Reveals New Cost-Saving Measures for West Seattle Link

Building a Procedural Hex Map with Wave Function Collapse
Who Writes the Bugs? A Deeper Look at 125,000 Linux Kernel Vulnerabilities
Routle - Think you know bus routes in Seattle?
SBOM - Sandwich Bill of Materials

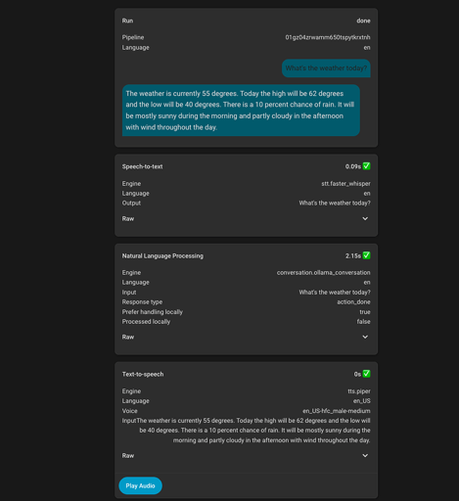
I use the HA Voice Preview in two different rooms and got rid of my Alexa Dots. I’ve been trying both speech-to-phrase and whisper with medium.en running on the GPU for STT, tried llama3.2 and granite4 for the LLM with local command handling
I’ve been trying to get it working better, but it’s been a struggle. The wake word responds to me, but not my girlfriend’s voice. I try setting timers, and it says done, but never triggers the timer.
I’d love to improve operating performance of my assistant, but want to know what options work well for others. I’ve been experimenting with an intermediary STT proxy to send it to both whisper and speech-to-phrase to see which one has more confidence.
How's your HA voice assistant going?
How's your HA voice assistant going? - Lemmy.World
If you’re using the Home Assistant voice assistant mechanism (not Alexa/Google/etc.) how’s it working for you? Given there’s a number of knobs that you can use, what do you use and what works well? - Wake word model. There’s the default models and custom - Conservation agent and model - Speech to text models (e.g. speech-to-phrase or whisper) - Text to speech models
Worst of Breed software
