Vendredi je serai au Forum ORAP pour discuter #HPC et #reproductibilité, et dire que les deux ne sont pas antinomiques.
http://orap.irisa.fr/52ieme-forum-reproductibilite/
Le tout en compagnie d’illustres personnages dont l’inénarrable @khinsen.

| Website | https://benoit.martin.eco |
Vendredi je serai au Forum ORAP pour discuter #HPC et #reproductibilité, et dire que les deux ne sont pas antinomiques.
http://orap.irisa.fr/52ieme-forum-reproductibilite/
Le tout en compagnie d’illustres personnages dont l’inénarrable @khinsen.
Tomorrow is the big day. I'll be defending my PhD thesis in front of a jury composed of:
- Reviewer: Achour Mostefaoui, Professor, Université de Nantes
- Reviewer: Gaël Thomas, Professor, Telecom SudParis
- Examiner: Bernd Amann, Professor, Sorbonne Université, LIP6
- Examiner: Annette Bieniusa, Professor, Université Technique de Kaiserslautern
- Examiner: Carla Ferreira, Associate Professor, Université NOVA de Lisbon
- Examiner: Peter Van Roy, Professor, Université Catholique de Louvain
- Supervisor: Marc Shapiro, Distinguished Research Scholar, Sorbonne Université, LIP6, Inria
- Advisor: Mesaac Makpangou, Researcher, Sorbonne Université, LIP6, Inria
The presentation is named "TTCC: Transactional-Turn Causal Consistency".
Abstract:
Today, stateful serverless functions are chained together through a message-based infrastructure and store their durable state in a separate database. This separation between storage and compute creates serious challenges that may lead to inconsistency and application crashes.
A unified consistency model for message passing and shared memory is required to avoid such errors. The model should ensure that multiple pieces of data remain mutually consistent, whether data is sent using messages or shared in a distributed memory.
Based on a well-known message-based model (actors) and a state model (transactional shared memory), we propose a unified communication and persistence model called Transactional Turn Causal consistency (TTCC). TTCC is asynchronous, preserves isolation, and ensures that the message and memory view are mutually causally consistent.
The defense will be presented in English, and will take place on Friday 21st of April 2023 at 2:00 PM (Paris time), at the Pierre et Marie Curie campus.
The defense will be streamed online: https://www.youtube.com/watch?v=mRCwQgOa3JY
Wish me luck !

I'm looking for a problem for my solution.
Who has experienced causal inconsistencies with stateful serverless functions?
For instance:
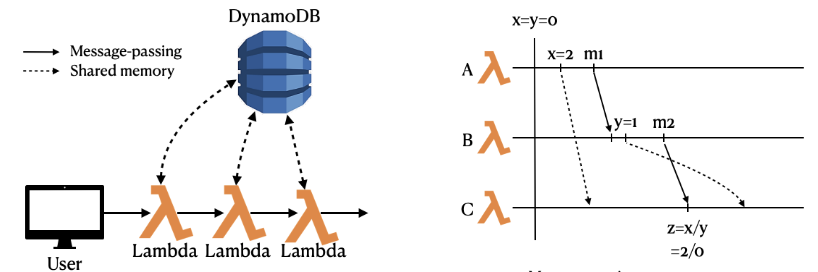
Initially, x=y=0 and are shared objects that functions A, B and C can read and update.
Function A updates x to value 2 and is chained to function B.
Function B on reception of function A's event, updates y to value 1 and is chained to function C.
Function C, on reception of function B's event and because of asynchrony and network delay, receives update to y late. Function C computes z=x/y (2/0) and crashes.
✨Updated version: book chapter on machine-learning model evaluation
To me, this text is very important, introducing readers to important and under-rated concepts, though most are neither new nor complicated
https://hal.science/hal-03682454/
It is not meant to be state-of-the-art or new (though it does contain recent results), but rather to be didactic and useful.
I believe that these materials can lead to more valid and more useful predictors. Validation is often a bottleneck.
1/3

This chapter describes model validation, a crucial part of machine learning whether it is to select the best model or to assess risk of a given model. We start by detailing the main performance metrics for different tasks (classification, regression), and how they may be interpreted, including in the face of class imbalance, varying prevalence, or asymmetric cost-benefit trade-offs. We then explain how to estimate these metrics in a unbiased manner using training, validation, and test sets. We describe cross-validation procedures –to use a larger part of the data for both training and testing– and the dangers of data leakage –optimism bias due to training data contaminating the test set. Finally, we discuss how to obtain confidence intervals of performance metrics, distinguishing two situations: internal validation or evaluation of learning algorithms, and external validation or evaluation of resulting prediction models.
