
🎞️ Representation learning on relational data to automate data preparation
My presentation at @ida : Data preparation
is crucial to analysis, but better pipelines can reduce
this need 🌟
https://speakerdeck.com/gaelvaroquaux/representation-learning-on-relational-data-to-automate-data-preparation
Many of these data patterns are in the examples of https://dirty-cat.github.io/




Representation learning on relational data to automate data preparation
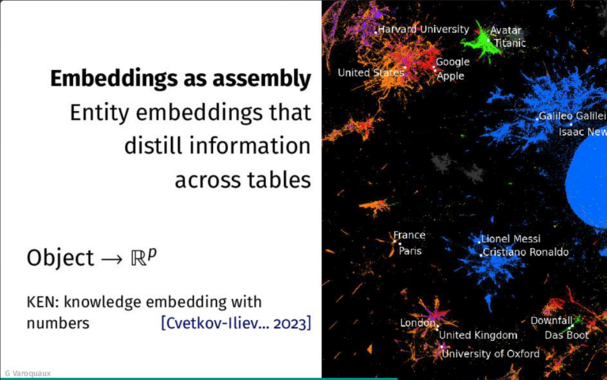
In standard data-science practice, a significant effort is spent on preparing the data before statistical learning. One reason is that the data come from various tables, each with its own subject matter, its specificities. This is unlike natural images, or even natural text, where universal regularities have enabled representation learning, fueling the deep learning revolution. I will present progress on learning representations with data tables, overcoming the lack of simple regularities. I will show how these representations decrease the need for data preparation: matching entities, aggregating the data across tables. Character-level modeling enable statistical learning without normalized entities, as in the <a href="https://dirty-cat.github.io">dirty-cat library</a>. Representation learning across many tables, describing objects of different nature and varying attributes, can aggregate the distributed information, forming vector representation of entities. As a result, we created general purpose embeddings that enrich many data analyses by <a href="https://soda-inria.github.io/ken_embeddings/">summarizing all the numerical and relational information in wikipedia for millions of entities: cities, people, companies, books</a> [1] Marine Le Morvan, Julie Josse, Erwan Scornet, & Gaël Varoquaux, (2021). <a href="https://proceedings.neurips.cc/paper/2021/hash/5fe8fdc79ce292c39c5f209d734b7206-Abstract.html">What’s a good imputation to predict with missing values?. Advances in Neural Information Processing Systems, 34, 11530-11540.</a> [2] Patricio Cerda, and Gaël Varoquaux. <a href="https://ieeexplore.ieee.org/abstract/document/9086128">"Encoding high-cardinality string categorical variables." IEEE Transactions on Knowledge and Data Engineering (2020).</a> [3] Alexis Cvetkov-Iliev, Alexandre Allauzen, and Gaël Varoquaux. <a href="https://ieeexplore.ieee.org/abstract/document/9758752">"Analytics on Non-Normalized Data Sources: more Learning, rather than more Cleaning." IEEE Access 10 (2022): 42420-42431.</a> [4] Alexis Cvetkov-Iliev, Alexandre Allauzen, and Gaël Varoquaux. <a href="https://hal.science/hal-03848124">"Relational data embeddings for feature enrichment with background information." Machine Learning (2023): 1-34.</a>






