'At some point you've got to make money': Goldman's top AI skeptic warns the clock is running out ahead of OpenAI and Anthropic IPOs
Probably the least controversial take on the threadiverse but i stumpled upon Ed Zitrons Blog like maybe two years ago. I’ve read a few posts of him since then and i just watch the shitshow unfold tbh. Its not that i 100% believe in his predictions. But he has made his point. I’m just an average fuck. I dont know shit. But it was so far the most believable and backed up assessment of the current AI situation.
I make barely enough money to afford my rent in bumfuck europe. How the fuck am i more informed about AI then some CEO? WTF.
- replacing human workers is their fondest dream so they want to believe so hard
- they have FOMO "everyone else is doing it and I don’t want to lose out"
- everyone else is doing it and if they didn’t do it and were wrong, it would be worse for their reputation than following the pack and being wrong
- c suite types talk to each other and they’ve formed an echo chamber
In summary, CEOs (of large public companies anyway - your mom and pop plumber could also be a CEO) are not smarter than the average person. Just more amoral and having the connections to be CEOs
It’s not that you’re more informed. It’s simply that you have to worry about consequences of mismanaging money where a CEO… well, hasn’t.
I want to see everyone hop on the IPOs and ride them all the way down to the floor!
Fuck AI
If I wasn’t convinced the entire financial system was fraudulent I would be shorting the fuck out of all of them
“The market can remain irrational longer than you can remain solvent”
Especially since Nvidia has reached the “too big to fail” level; guess who’s gonna pay again for the upcoming crisis?
Source? Not doubting you, just would like to know the criteria.
There isn’t a completely objective criteria, from Wikipedia:
Federal Reserve Chair Ben Bernanke also defined the term in 2010: “A too-big-to-fail firm is one whose size, complexity, interconnectedness, and critical functions are such that, should the firm go unexpectedly into liquidation, the rest of the financial system and the economy would face severe adverse consequences.”
NVIDIA currently makes up nearly 7.5% of the S&P 500 (not to mention that they have invested a lot in the other companies and those companies have invested in NVIDIA). If they were to suddenly be liquidated I’d say that would cause ‘severe adverse consequences’ to the economy.
And it would likely cause a ripple to other tech companies, which which make up roughly 1/3 of the entire US stock market.
Thanks, especially for the figures, that helped a lot.
Thank you indeed. On my side I only remembered the news back in November that nvidia weighted 16% of the US GDP. Now of course comparing valuation and GDP is not really meaningful but the idea stuck.

We’ll burn more and more coal to power air conditioners to deal with unbearable global warming until that’s no longer possible.
The financial markets are the same. No reasonable person believes any of this is sane or sustainable. But what happens when the music stops? Very few chairs.
I think investments, 401Ks and retirement funds will hop on SpaceX and AI and the mass will complain for a bit until the next news cycle.
I’m not much of an AI skeptic compared to most on Lemmy. I think the technology is incredibly useful and probably beneficial to society if we can remove the control of the ruling class.
That said I truly don’t understand how the AI business model is supposed to work. I’m sure there is some market for businesses, governments, etc., basically people who have too much money who may want to pay for the latest and greatest models.
But I don’t really see the average consumer doing this when slightly less good versions will almost certainly be available for free. And the above customers will not be able to support the level of investment that’s going on right now.
technology is incredibly useful and probably beneficial to society
For what? It’s not reliable enough to actually automate anything and people that use it regularly inevitably stop checking the output and start falling victim to hallucinations. It’s pretty good at rifling through social media posts which I don’t think is good for society and it’s OK as a frontline support system but even that they normally go too far and just make it infuriating
I automate plenty with it, no you cant be an idiot about it but i can do what used to take me weeks in hours with it.
Yeah I think Lenny’s generic take is heavily colored by the absolute morons using it moronically. That’s a large number of people because lots of people are…well, morons. But you can definitely use it in productive ways. Keeping a human in the loop right now I think is very prudent, for cost and reliability reasons, but man does it decrease drudgery in capable hands.
People are scared because they think they could lose their jobs. Even if they say out loud they don’t think it will happen and that they think AI is useless. They need AI to fail for peace of mind.
If anything they’re most at risk for losing their job due to a stubborn refusal to adopt technology. What people don’t realize is that we don’t live in an ideal world where the optimal solution is the only way. Even if LLMs are less than perfect, there’s a scenario where it remains commonplace because it’s what’s in style. The stubborn abstainers will find themselves left behind when everyone else is leveraging it to complete mundane tasks much faster and checking the work.
We already live in a world full of cumbersome enshittified technology. There’s nothing we can do but make do with what we have. At this point people are dreaming if they think the AI bubble will pop and the technology will be shelved. It’s not going away. It’s already demonstrated usefulness. That it’s not turning a profit is a different story.
Maybe some others are simply scared that they don’t have the expertise to check the work of LLMs in the first place.
It’s not reliable enough to actually automate anything
This is half true. It’s not reliable enough to automate an entire job but it is reliable enough to automate tasks that would otherwise take a lot of time, usually related to sifting or searching data.
If I need to look through a massive set of data like Google for something thst I can only describe with an explanation, the LLM will do a much faster job actually finding what you need rather thsn spending an hour manually sorting through SEO slop.
You don’t even need the cloud models for this, you can slap SearXNG onto a local model at home.
It’s basically just an autocomplete search on steroids which is its biggest advantage. Any documentation you need is immediately accessible, which is especially useful if you have zero experience with something niche or new.
Now actually getting the LLM to consistently generate output is a completely different story lol.
We call that vibe coding.
If I need to look through a massive set of data like Google for something thst I can only describe with an explanation, the LLM will do a much faster job actually finding what you need rather thsn spending an hour manually sorting through SEO slop.
You could also use any other search engine since Google intentionally wrecked their search, and use the adblock list that filters out the seo slop. Just as efficient and less glacier melting
, usually related to sifting or searching data
No matter the harness, no matter the spell, no matter the model, it is failing me daily in that regard, in my field of expertise. And the failures are random between inconsequential to grandiose.
Heck, the thing it should be doing best - summaries - are constantly either missing the point or focusing on wrong take.
It doesn’t need to fully automate anything to make people more productive. And I think there’s ample evidence it can greatly increase productivity in some fields. We’re in the bumpy phase of finding out how much human supervision is needed in each field so you’re bound to hear about ways it has been misused but everyone I’ve talked to who uses it professionally thinks it helps them get a lot more done than without it.
So far I’ve saved at least 100 hours of my life having LLMs pump out scripts for me instead of writing them by hand. Its better and faster at it than I am, and its easy enough for me to validate a simple script. The inherent flaws in the technology don’t change the fact that it can provide utility, and that utility has enough value that even if the technology doesn’t progress from here, even with its inherent flaws, it is not going away.
It is useful for programming, I know a lot of people here don’t want to hear that, but denying it now is being willfully ignorant. No it isn’t good enough that you can tell it “just go do the thing” and then accept what it gives you without checking it, but using it as a tool as a professional can very much improve your work and how quickly you do things. For me recently I used it to unpick a nasty race condition that was occasionally causing a program I was working on to lock up and couldn’t figure out why. It took some back and forth with it but it did help me figure it out when before I had been stumped.
it’s not useful for programming and it makes code more verbose, poorly structured, and requires too many attempts to get a mildly useful block.
poorly structured,
yes, that’s bad
requires too many attempts to get a mildly useful block.
yes, that’s bad
more verbose,
How is that bad? I can’t count how many times I’ve revisited my work a year or more later, and wondered what I was thinking, having taken 2 minutes to parse something dense that I wrote, and then thought “why didn’t I make this a little clearer at the time?”
More verbose does not imply that is is more clear, it is often rambling and not even accurate.
rambling and not even accurate
Ah yes, that makes sense; thank you.
correct. it’s long winded code that could be written a lot more succinctly.
I do work in software, and my main focus is on code review, as we work with money, and things have happened due to many factors.
I DO NOT want any more work being done. Fuck that. It’s hard reviewing ‘normal’ amount of code, multiplying it will backfire horrendously.
I do not need people not being able to figure out their bugs. It’s the most important part of the job, and not being able to fix it quickly costs us a lot.
If you need to fix something in a library you don’t understand… maybe you should review it before using? There are situations when it’s not possible, usually in low risk fields, frontends and such, but even then, we (IT in general) produce so much shit for no real gain. And we need LESS of it, not more.
Everyone I work with that uses it is worse at their job than before they started using it, and I’ve lost the ability to teach them how to actually do good work because telling the c-suite they’re 10x now (even though their producing only slightly more code and more issues) makes the c-suite happy. I could believe that some people have made small improvements to their workflows but its obvious to anyone competent that it’s not as big as an improvement as they’d have you believe and the vast majority is just people getting addicted to the slot machine, deskilling, and creating inferior output.
It’s clearly a controversial thing to say on the fediverse, but everyone must realize that AI is another tool - a sometimes faulty, sometimes great tool. A professional can use it well, a careless person can use it carelessly. But it is a tool that can help in certain cases. It’s a nuanced thing, which many people unfortunately have trouble accepting. It has flaws, yes. It also has benefits. This shouldn’t be controversial to say.
That of course doesn’t guarantee that providing that tool must be profitable. It may well be that providing AI models is just too expensive to actually make sense, at least as it is right now.
but using it as a tool as a professional can very much improve your work and how quickly you do things.
Maybe it’s just my 20 yoe, but that has so far not been my experience with it. It is improving, but definitely not there yet. Even standard boiler plate I can typically bang out faster than asking the AI to do it and then needing to double check it’s work because it somehow still manages to screw that up occasionally. Sometimes it does manage to be better than one of the juniors, but using it that way also cuts the legs out from under the career development pipeline which will result in an intermediate and senior dev drought down the road.
Even standard boiler plate I can typically bang out faster than asking the AI to do it
The people that claim it helps with boilerplate clearly never took the time to learn how to sed/awk, mustache templates, write a perl/python/etc script, use the regex find/replace in their editor, use the keyboard macro in their editor, use snippets in their editor and I’m sure offer ways that aren’t immediately coming to mind that have existed forever and won’t hallucinate. They’re the ones that were not highly skilled in the first place and they’re vexingly successful at convincing newbies and laymen to listen to them about LLMs instead of the actual skilled people that actually know what they’re talking about.
Which model are you using? My experience is that it can definitely do “standard boilerplate”. What programming language are you using?
If you don’t understand why AI is going to be akin to a failed industrial revolution, maybe give this scenario a read. Here a think tank has written a forcast on how AI will potentially unfold and influence the global future.
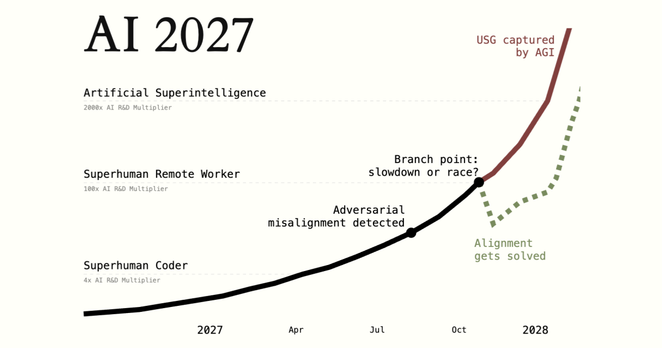
They worked on it in stages—starting with early ideas up to mid-2025, then continuing to build from there. But instead of sticking with that first draft, they threw it out and started over from scratch.
They also didn’t settle on just one ending. After finishing their first version (the one marked in red), they created a second, more hopeful outcome starting from roughly the same point. That version also went through several rounds of revisions.
And this wasn’t made up out of nowhere—it was based on about 25 tabletop exercises and feedback from over 100 people, including dozens of experts who work directly in AI governance and AI technical fields.
including dozens of experts who work directly in AI governance and AI technical fields.
All of those people are fucking clowns and you know it. They’re these morons. en.wikipedia.org/wiki/Rationalist_community
I didn’t know it and although the read was interesting to me I didn’t immediately make the connection. Disregard the post, actually looking at the cross-reference I’ll go ahead and delete the comment.
we are all free to listen to eachother’s point of views, then arrive at our own conclusions .
Sure, but I’m not going to pretend for a second that the pseudointellectual masturbation of “rationalists” is worth a damn just because their narratives were useful to capalist oligarchs so some people call them “experts” now. What a farce
Fanfic.
They predict “reliable agent” by 2026. I think they’ve already failed. AI is still unreliable tool. It’s a very useful tool but there is no signs of any change to being reliable. Particularly odd is their claim that a new and better AI will come out from the work of the old unreliable AI. This is unlikely given that it has already been shown that AI trained on other AI degrades, not improves.
The business model should be that with economies of scale they could provide compute much cheaper than average consumer can buy to run locally. So yeah, that means they gotta be able to support these $20/mo plans indefinitely.
If they jack up the prices i can just buy a 128gb ryzen ai machine for the price of $200/mo claude for a year
I’m not an expert but my understanding is most of the computation is in the training. The actual queries are not too difficult to manage. So I think that’s what makes it more difficult to monetize because you’re trying to position yourself as a digital gatekeeper for work that has already been done. Yes, some industries have survived in this position but it limits the amount of profit you can make because there are always ways to copy someone else’s homework.
Local is potentially even cheaper than that. This guy talks about how to get 17 t/s with a GTX 1060 that has 6GB of VRAM on the Qwen 3.6 35B MoE model: m.youtube.com/watch?v=8F_5pdcD3HY. He’s using a fork of llama.cpp with TurboQuant and his newest video made after this one is using an even more optimized 28B version of the model. I have cmake running in a Dockerfile at the moment and we’ll see how this performs on my $800 laptop with a RTX 4060.
I’m also impressed how good OpenCode is compared to Claude Code. Qwen 3.6 is not quite as good as Claude, but it also doesn’t cost $200 a month with usage limitations and a company training their models on your data. If it’s anywhere near “good enough”, I can see this being a daily driver.

Running a 35B AI Model on 6GB VRAM, FAST (llama.cpp Guide)
The business model should be that with economies of scale they could provide compute much cheaper than average consumer can buy to run locally.
That business model assumes that the huge cloud models will always maintain a gap worth paying for, compared to the local models. I’m just not convinced that the average consumer will need cloud models for summarizing their emails or the news of the day.
And for actual costs of their data centers, there literally aren’t enough humans in the world where $20/month AI spending per person will help them break even. They’ll need to sell big accounts (many businesses spending billions per year) in order to break even.
This isn’t directed at you specifically, but just the broad sentiment that people are coming now OK with AI even though people kinda I guess forgot that like AI stole and ripped all of our information books. Music works of art all of it’s stolen ya know. But I’ll digress it doesn’t matter anymore.
But I’ll digress it doesn’t matter anymore.
Exactly. There is no ethical consumption.
The Internet that you’re posting on was built on top of a military network intended to provide redundant communication in the event of a global thermonuclear war. The satellites that provide you with GPS were created in order to more accurately drop bombs and guide armies. The rockets that put them in space exist because of research into methods of delivering nuclear weapons.
Your smartphone likely contains components built by slave labor, you almost certainly consume food products resulting from child labor. Your clothing as well.
The world is built on all manner of immoral things. ‘Stealing’ information (which presupposes the idea that a person can own knowledge, which I disagree with) is incredibly mild.
On top of that, the advances in AI are happening independent of LLMs. The advances in machine learning that made LLMs possible apply to all kinds of different areas that have nothing to do with language, music, or art.
LLMs just happen to be the easiest kind of AI to train because humanity has spent millennia storing language in books and the Internet provides a massive amount of data as well.
The Internet that you’re posting on was built on top of a military network intended to provide redundant communication in the event of a global thermonuclear war.
Responding to this part alone: that’s not actually true.
The intent of arpanet, the direct predecessor to the Internet, was to make it easier for universities to use high powered computer resources located at national laboratories, as well as making it easier to distribute software updates. The person who initially pushed for it’s creation wanted “an electronic commons open to all, 'the main and essential medium of informational interaction for governments, institutions, corporations, and individuals '”. They secured funding for the initial computer science labratories, os research that underpin everything, and the foundation for the “INTERgalactic NETwork”.
Arpa was, at the time, the advanced research project agency. They were under the DoD, but they filled a role closer to the NSF today.
In designing the system they referenced work done by people who were studying robust communication networks. At the time that meant the phone system and nuclear weapons. The research, however, was applicable to any unstable network, and so had particular interest to them because computers had terrible reliability and they wanted to not have to call people if they discovered they had turned off a computer halfway between New York and LA.
The closest thing it has to a cold war military objective is to help us win the research race and spite the Soviets. It can withstand a nuclear attack, but that’s just because that’s the easiest way to make it survive a farmer with a backhoe accidentally hitting a wire.
They were under the DoD, but they filled a role closer to the NSF today.
DARPA was defense projects funded by the military for the military. NSF predates DARPA by 8 years. DARPA did not fill a role closer to the NSF today.
It was after ARPANET was created for the military that it was expanded into general university use by NSF into NSFNet in 1986.
(I worked for Bob Kahn and Vint Cerf in the early 90’s.)
DARPA was originally ARPA. They were under the department of defense but their project scope wasn’t limited to defense projects. The reorganization that rebranded the agency as DARPA and made it defense focused ostensibly saw the non-defense oriented moonshot project responsibility transfer to the NSF, although the funding shift wasn’t proportional.
The order of creation isn’t exactly relevant to how responsibilities have shifted.
It’s kinda like how, for the longest time, presidential security was handled by the Treasury department. It wasn’t because presidential security was considered a financial matter, but because that’s where it fit.
www.darpa.mil/news/features/arpanet
Secure communications and information-sharing between geographically dispersed research facilities were among the ARPANET’s original goals.
From your link to the arpanet wiki:
Building on the ideas of J. C. R. Licklider, Bob Taylor initiated the ARPANET project in 1966 to enable resource sharing between remote computers.
Sutherland and Taylor continued their interest in creating the network, in part, to allow ARPA-sponsored researchers at various corporate and academic locales to utilize computers provided by ARPA, and, in part, to quickly distribute new software and other computer science results.
There’s a big difference between ARPA funded labs and general university usage.
I’m not sure why it would matter that you worked for them in the early 90s. That doesn’t exactly give you a privileged insight into the creation of ARPANET.
information-sharing between geographically dispersed research facilities
Research facilities doing DOD research.
I’m not sure why it would matter that you worked for them in the early 90s.
The president of the company got Vint and Bob on board because he was their military liason at Darpa.
The project I worked on was partially funded by Darpa. We reported weekly updates to a Lt Colonel.
The Internet was originally by the military and for the military and only later handed off to universities.
Yes, I will just take your word for it over the word of the original people involved.
You keep talking about DARPA, when they’re not the same organization that backed ARPANET. Arpanet came before laws were passed saying DARPA could only fund projects directly related to defense.
ARPA was military.
“From 1958 to 1965, ARPA’s emphasis centered on major national issues, including space, ballistic missile defense, and nuclear test detection.[21] During 1960, all of its civilian space programs were transferred to the National Aeronautics and Space Administration (NASA) and the military space programs to the individual services.[22]
This allowed ARPA to concentrate its efforts on Project Defender (ballistic missile defense), Project Vela (nuclear test detection), and Project Agile (counterinsurgency R&D programs), and to begin work on computer processing, behavioral sciences, and materials sciences. The DEFENDER and AGILE programs formed the foundation of DARPA sensor, surveillance, and directed energy R&D, particularly in the study of radar, infrared sensing, and x-ray/gamma ray detection.”
ARPA was renamed to DARPA in 1972.
"DARPA supported the evolution of the ARPANET (the first wide-area packet switching network), "
There was no Internet in 1972. It was ARPANET which was run by DARPA. The D was added to reaffirm that ARPA was the department of defense, not civilian research.

I think it matters. I do think the technology is interesting and useful, but if you create something using AI models based on license violations then what stops someone from taking it? What standing would you have in court to say that it’s yours? Why is the AI model “fair use” but a thing made with it is proprietary? These are things yet to be fully determined, but given that training and running AI is not cheap these companies are building on sand IMO.