RE: https://tldr.nettime.org/@tante/116605858023186072
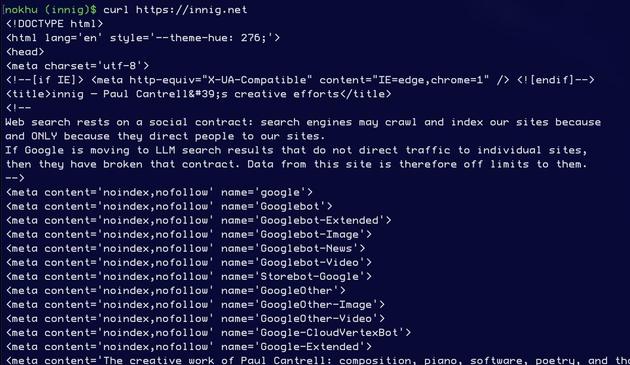
Google Search rests on a social contract: their bots can crawl our sites, they can index our sites, and they can show excerpts of our sites because
and •only because•
they send people to our sites. •Our• sites, our words, with our design, with our links, with our context and our aesthetics, shared the way we want to share them.
Google is announcing — unambiguously and with great fanfare — that they are now fully breaking that already-ragged contract. We should reciprocate.
1/2
 🍀
🍀