RE: https://dair-community.social/@emilymbender/116604745957981805
"links will become an afterthought" is not even coded language for "the rest of the internet is merely training data and we will own the entire means of accessing information online"
RE: https://dair-community.social/@emilymbender/116604745957981805
"links will become an afterthought" is not even coded language for "the rest of the internet is merely training data and we will own the entire means of accessing information online"
as Dr. Bender says upthread, the Rethinking Search paper just says this explicitly, also AMP, etc. I only mildly edited their figure here
The shift to "search journeys" is just another way of referring to "whole life immersive surveillance" where the intention is to slowly train you to expect more and more of your personal information to be visibly injected into search results as a surface for "personalization" and eventually move towards "zero-query search" where advertisements-i-mean-helpful-information are proactively volunteered to you.
this language appears in full form as early as 2018 and was chilling even then:
The zero-query search paradigm can be expressed with the slogan “the query is the user.” In practice, the context of the user is used to infer information needs. (Entity Oriented Search)
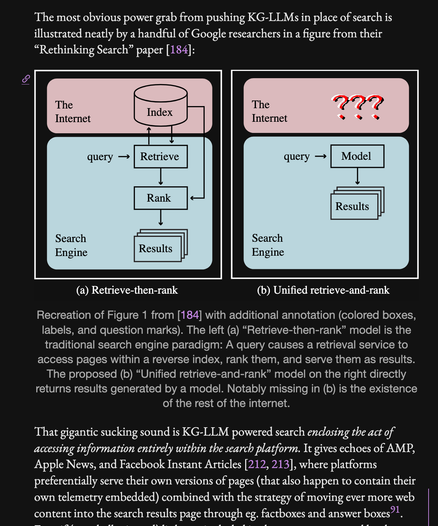
There IS NO LLM USE not associated with the project to seize all information as a product. That is the WHOLE gamble being made that is driving all those billions into getting as many people as possible dependent on the most preposterously expensive and inefficient model of computing ever devised. It is only worth it if the upside is owning the whole economy.
Every step you take towards building LLMs into your daily habits and work ratchets the spring tighter on the mousetrap until, surprise! It clamps shut while your whole ass is wrapped around the cheese. Don't make me laugh with local models nonsense, if you think that those don't get deprecated the moment they pose the slightest whiff of a threat to the profit model - meta isn't releasing weights to be nice, it's to capture labor and control the tooling space. Don't be a sucker.
Also almost every time I see local models mentioned it's someone using them to derail a conversation about the harms of LLMs. Makes them a very useful tool for those big companies to keep doing all the damage they want and then just have someone say "but local models" when the companies' extremely antisocial policies are hilighted.
@gbargoud @jonny So many of these conversations seem conceptually mushy to me. The benefits and harms of LLMs can be discussed separately from the benefits and harms of big tech.
Feels like the harms of big tech are very obvious and keenly felt whereas I'm still uncertain about the harms of LLMs specifically. They seem to make specifically crime easier and contribute to skills atrophying.
I'm trying to get clear on this stuff myself, it's not easy.
@jackperkins yeah, that's the problem with this "big tech" label, what does that even mean? I'm using it as shorthand for big tech companies that are using their technology to harm consumers and extract value out of them. Like Amazon, Google, Meta.
Arguably Mistral is not "big tech". Arguably DeepSeek doesn't fall until this either.
I just helped my partner run a campaign against big tech here in Denmark, and charting a course around this question of what is and isn't "bad" in tech .. yeah, its complicated. She got a lot of criticism for recommending Signal for instance, but in thinking about the harms of big tech, I kind of keep coming back to the book Surveillance Capitalism. Had lots of flaws but useful in thinking about how these companies extract value in really sinister ways.
@joshbuddy @jackperkins "Arguably Mistral is not 'big tech'. Arguably DeepSeek doesn't fall until this either."
False. Mistral is a metastatization of big tech—it was founded by Google and Meta people and therefore surely was founded with the same diseased capitalist assumptions that pervade all tech companies. DeepSeek was founded by an entrepreneurial grifter whose purpose for exploiting AI is stock-market gambling—there's no more corrupt purpose for exploiting technology than trying to swindle money through market gambling.
@joshbuddy a million is one thousand times smaller than a billion. many startups received handfuls of millions of dollars in investment, whereas openai burns something like a billion a month in operating costs.
what is the cost mistrail or deepseek paid to produce their "open" models?
@jackperkins to be clear, I would certainly call OpenAI big tech, and I'm not at all a fan of what they do. And granted that creating any large language model is probably capital intensive because of acquiring the source material and the GPU and energy costs.
Curiously, it looks like at least one group is working on distributed training, so more like how the OpenGo weights were made
https://www.primeintellect.ai/blog/intellect-1
Mistral looks like they took very traditional funding. DeepSeek looks like they are funded out of a hedge fund.
Gosh, this is all pretty depressing. Technically, it should be possible to make a completely open LLM, like the INTELLECT-1. I know that money in tech means we'll eventually get screwed. The only silver lining in this is at least the open weights are free beer, no one can take them away and they are useful for people.
After reading Winners Take All I just wanted to exit tech. It's hard not to look at the direction of all this and just wish for a time machine or something.

We're excited to launch INTELLECT-1, the first globally-distributed training run of a 10-billion-parameter model, inviting anyone to contribute compute and participate. This brings us one step closer towards open source AGI.
