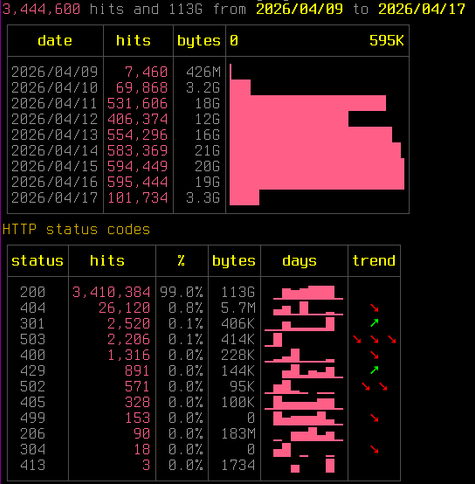
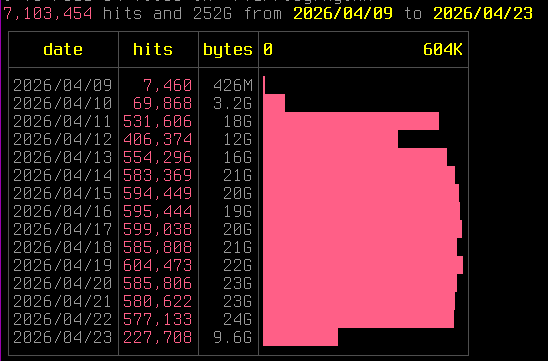
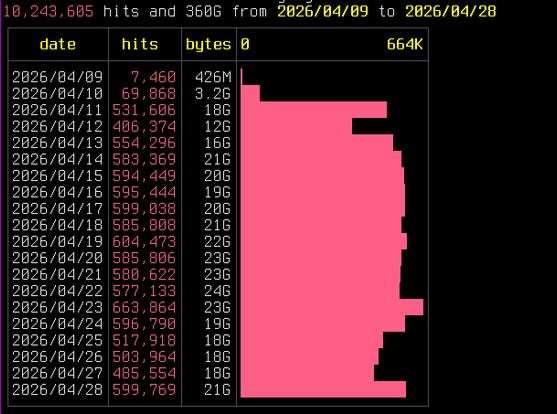
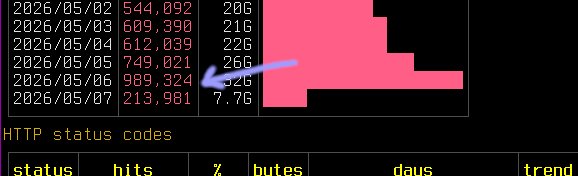
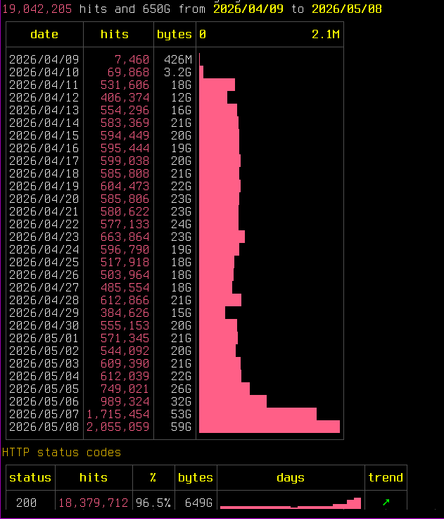
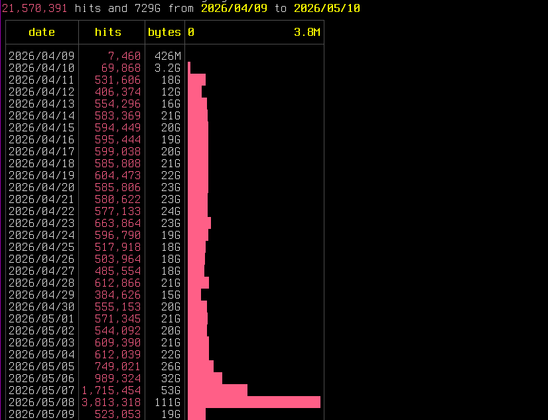
Pleased to share a page and explainer for the AI tarpit project Science is Poetry, with legal statement, rationale(s), and a few deployment notes:
https://julianoliver.com/projects/science-is-poetry/
The page may grow a bit. Just wanted to get it out the door.