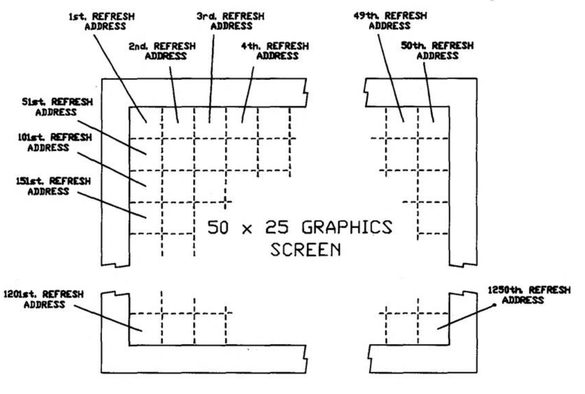
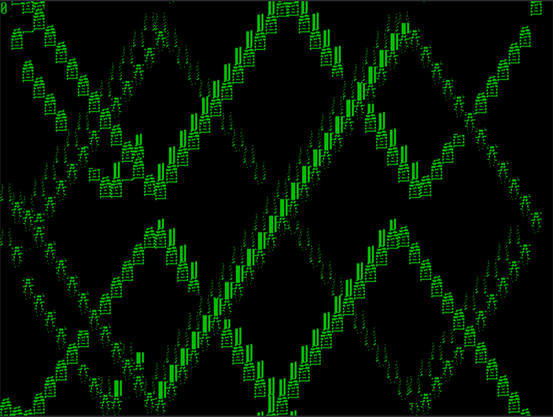
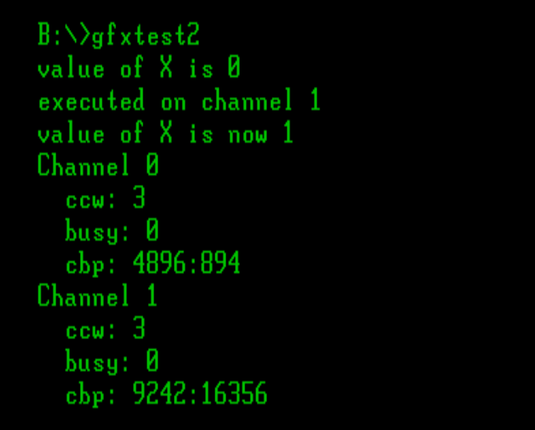
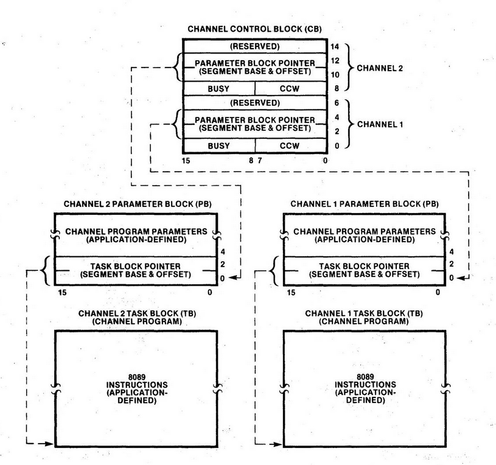
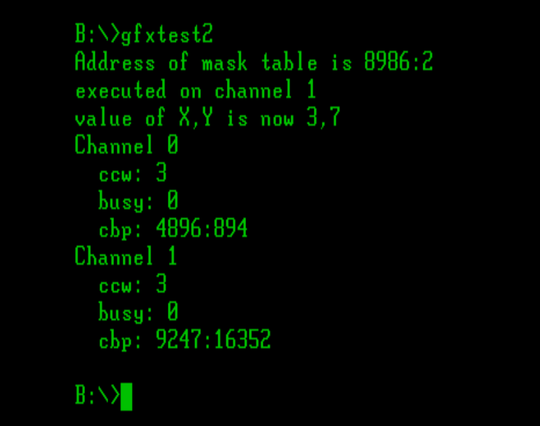
I want to do some more stuff with Apricot graphics. See, the thing is, these computers don't really _have_ graphics. What they have is a character mode with 16x16 pixel cells. Every pixel is addressable, but every pixel exists inside redefinable character memory, so you have to know where the particular character is in memory to modify its pixels. Which means there's different ways you can map the "characters" to the screen.
I had originally set this up in the usual way, with each cell following the next in rows and columns. But I realized much later that if you arrange the character cells in columns, every column becomes a contiguous region of 16-bit words. The math becomes simpler, and the whole thing runs faster.